Building Serverless PySpark Jobs with EMR-Serverless and MWAA

Introduction
Amazon Web Services (AWS) provides a rich ecosystem of tools and services to tackle big data challenges. Two powerful components that stand out are Amazon EMR (Elastic MapReduce) and Amazon MWAA (Managed Workflows for Apache Airflow).
In this blog, we will explore how the combination of EMR Serverless PySpark jobs on MWAA revolutionises big data processing and analysis.
EMR Serverless Overview:
With EMRServerless , you pay only for the resources you consume while your jobs are running, and you have the option to pause your cluster when it is not in use to save on costs. EMR serverless also provides built-in integrations with other AWS services, such as Amazon S3 and Amazon DynamoDB, which can make it easier to store and access data for your big data workloads.
MWAA Overview :
MWAA stands for Managed Workflows for Apache Airflow MWAA , which is a fully managed service provided by AWS. Apache Airflow is an open-source platform used for orchestrating, scheduling, and monitoring complex data workflows. It allows you to define, schedule, and manage data pipelines as directed acyclic graphs. MWAA simplifies the deployment and management of Apache Airflow environments. It handles the underlying infrastructure, including provisioning servers, scaling, patching and maintenance, so that you can focus on designing and running your data workflows.
Implementation:
By integrating EMR serverless PySpark jobs with MWAA, you can create sophisticated data processing pipelines that are orchestrated and managed seamlessly. MWAA’s support for dynamic scaling ensures that resources are allocated efficiently based on job requirements, further optimising cost and performance.
PySpark Code
The below PySpark code to read from the post gres employee table and insert into the other employee_v1table.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("ETL Pipeline").getOrCreate()
# COMMAND ----------
# Credential
db_properties = {
"user": "postgres",
"password": "******",
"driver": "org.postgresql.Driver"
}
# Credential
postgres_url = "jdbc:postgresql://sparkemr.ctrfy31kg8iq.ap-southeast-2.rds.amazonaws.com/customer"
#Table Details
table_name = "employee"
table_schema = "public"
# Read from Postgres table
df = spark.read.jdbc(url=postgres_url, table=f"{table_schema}.{table_name}", properties=db_properties)
df.show()
table_name="employee_v1"
# Write from Postgres table
df.write.jdbc(url=postgres_url,
table=f"{table_schema}.{table_name}",
mode="append",
properties=db_properties) ```VPC Configuration using Terraform
provider "aws" {
region = "ap-southeast-2" # Change to your desired AWS region
}
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "5.1.1"
# VPC Basic Details
name = "sparkemr-dev"
cidr = "10.0.0.0/16"
azs = ["ap-southeast-2a", "ap-southeast-2b","ap-southeast-2c"]
private_subnets = ["10.0.16.0/20",
"10.0.32.0/20","10.0.64.0/20"]
public_subnets = ["10.0.0.0/20",
"10.0.48.0/20","10.0.80.0/20"]
# Database Subnets
#create_database_subnet_group = true
#create_database_subnet_route_table= true
#database_subnets = ["10.0.151.0/24", "10.0.152.0/24"]
#create_database_nat_gateway_route = true
#create_database_internet_gateway_route = true
# NAT Gateways - Outbound Communication
enable_nat_gateway = true
single_nat_gateway = true
# VPC DNS Parameters
enable_dns_hostnames = true
enable_dns_support = true
public_subnet_tags = {
Type = "sparkemr-public-subnets"
}
private_subnet_tags = {
Type = "sparkemr-private-subnets"
}
tags = {
Owner = "Jay"
Environment = "dev"
}
vpc_tags = {
Name = "sparkemr-dev"
}
}MWAA DAG
A Directed Acyclic Graph (DAG) is a graph object that represents a workflow in Airflow. It is a collection of tasks in a way that shows each task’s relationships and dependencies. DAGs contain the context of task execution. In MWAA, we will keep DAGs in S3.
Step 1: Create the MWAA with required IAM policy and VPC dependencies.
Step 2: Add the below DAG in the specified S3 bucket.
The below DAG creates an EMR serverless application and runs the PySpark job on it. Once the job has been completed successfully the dag will delete the EMR applications.
from datetime import datetime
from airflow import DAG
from airflow.providers.amazon.aws.operators.emr import (
EmrServerlessCreateApplicationOperator,
EmrServerlessStartJobOperator,
EmrServerlessDeleteApplicationOperator,
)
# Replace these with your correct values
JOB_ROLE_ARN = "arn:aws:iam::*******:role/AmazonEMR-ExecutionRole-*******"
S3_LOGS_BUCKET = "jay-airflow"
DEFAULT_MONITORING_CONFIG = {
"monitoringConfiguration": {
"s3MonitoringConfiguration": {"logUri":"s3://**-airflow/logs/"}
},
}
#
with DAG(
dag_id="emr_serverless_job",
schedule_interval=None,
start_date=datetime(2023, 1, 1),
tags=["postgres"],
catchup=False,
) as dag:
network_config = {
'subnetIds': [ 'subnet-0d80705cb360536b5','subnet-0c84b6541e43ee23b','subnet-018773ddec10cd902'
],
'securityGroupIds': [
'sg-0357c733a2afebcc1',
]
}
create_app = EmrServerlessCreateApplicationOperator(
task_id="create_spark_app",
job_type="SPARK",
release_label="emr-6.7.0",
config={"name": "EMR-Airflow"
,"networkConfiguration": network_config
},
)
application_id = create_app.output
job1 = EmrServerlessStartJobOperator(
task_id="start_job_1",
application_id=application_id,
execution_role_arn=JOB_ROLE_ARN,
job_driver={
"sparkSubmit": {
"entryPoint": "s3://***-emr/sparkemr.py",
"entryPointArguments": ["s3://jay-emr/outputs"],
"sparkSubmitParameters": "--conf spark.jars=s3://jay-emr/postgresql-42.6.0.jar --conf spark.executor.cores=1 --conf spark.executor.memory=4g --conf spark.driver.cores=1 --conf spark.driver.memory=4g --conf spark.executor.instances=1"
}
},
configuration_overrides=DEFAULT_MONITORING_CONFIG,
)
delete_app = EmrServerlessDeleteApplicationOperator(
task_id="delete_app",
application_id=application_id,
trigger_rule="all_done",
)
create_app >> job1 >> delete_appStep 3: Open the MWAA user interface (UI) and find the below DAG.
 MWAA Airflow
MWAA Airflow
Step 4 :In the demo we are manually triggering the job.
The create_spark_app will create the EMR Application.
Start job will run the spark job on the EMR applications.
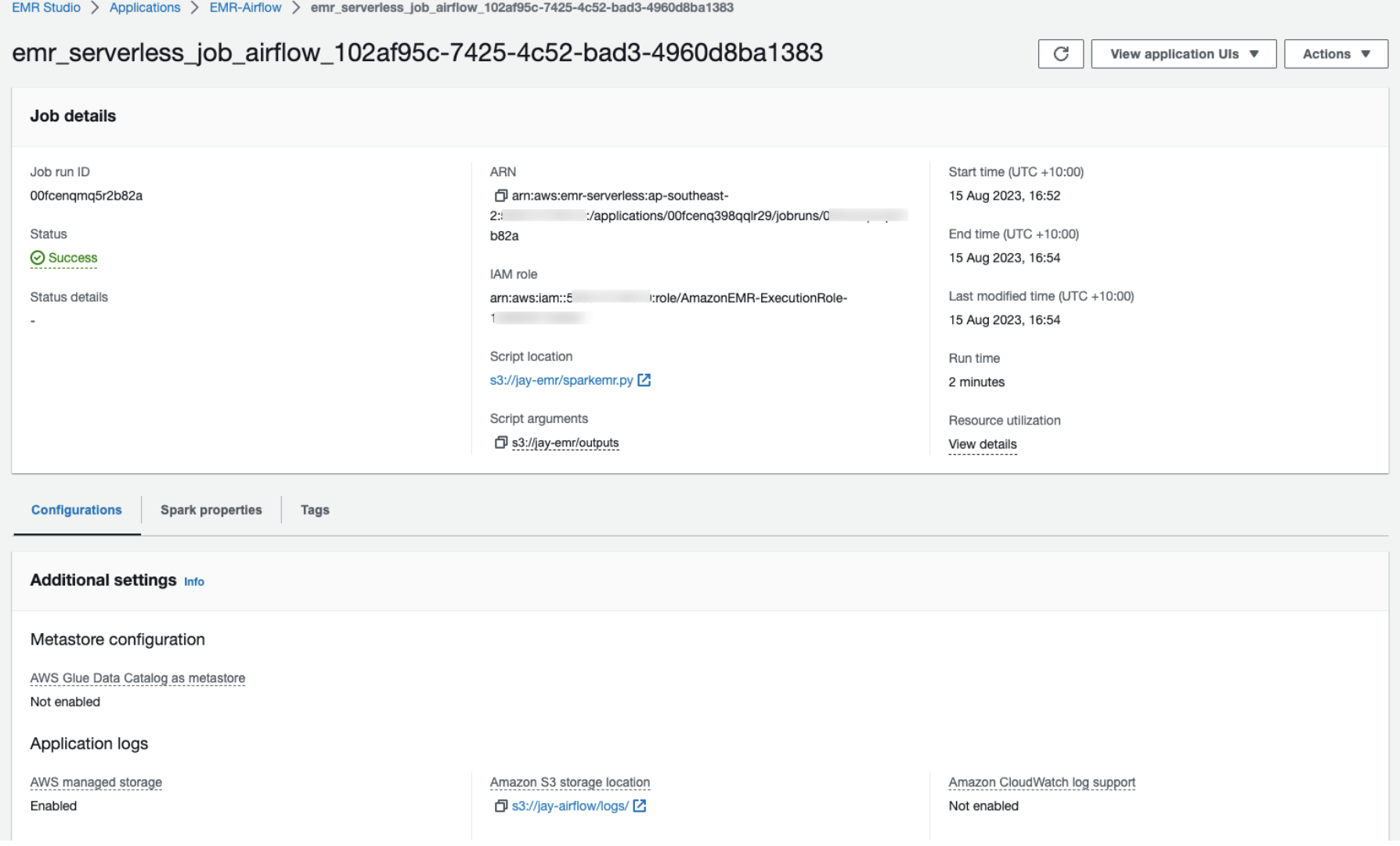 EMR Pyspark
EMR Pyspark
Delete_app will delete the EMR application which was created as a part of the first step once the spark job has completed.
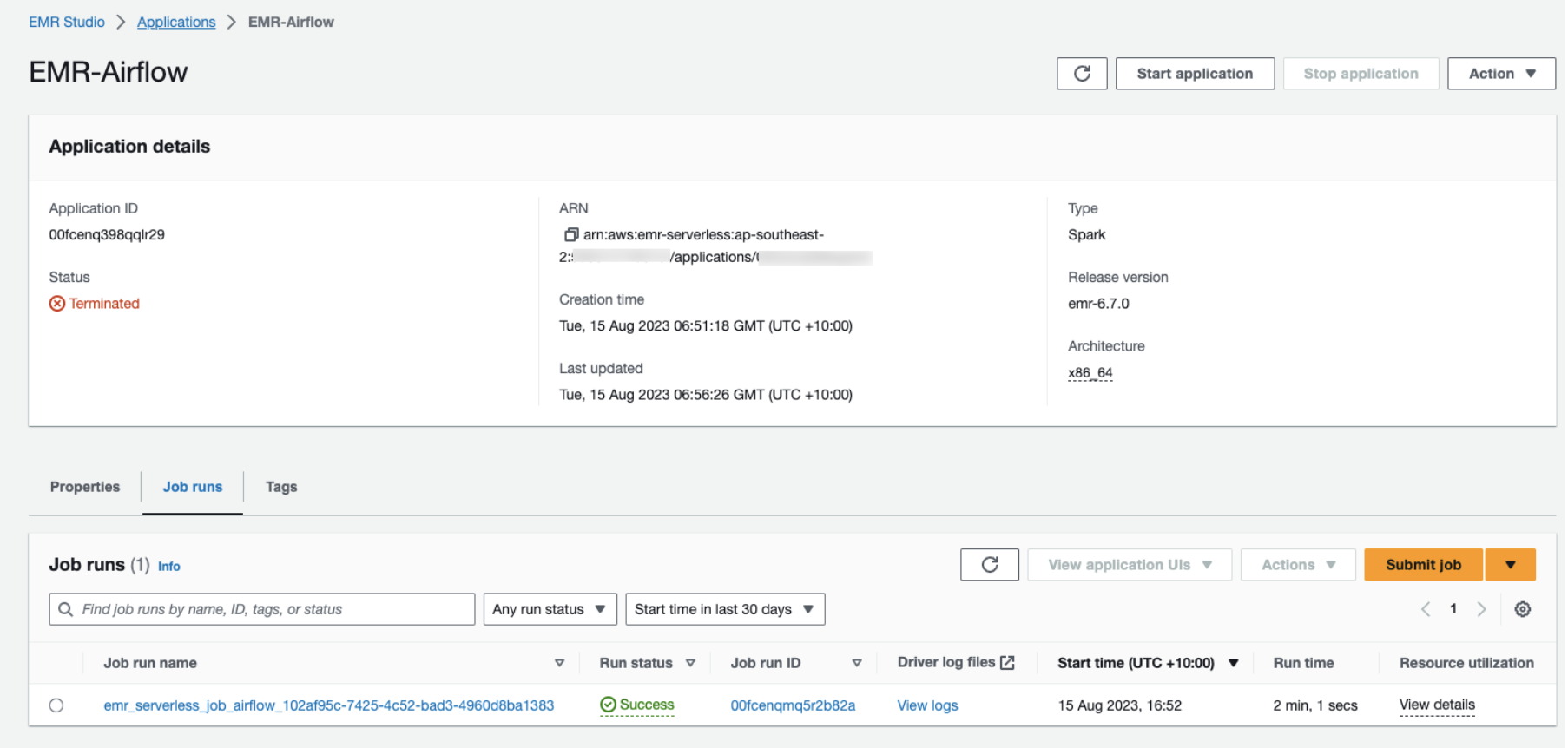 EMR Pyspark
EMR Pyspark
Result
 EMR Result
EMR Result
Benefits of combining EMR serverless PySpark jobs with MWAA:
Cost efficiency: By leveraging serverless PySpark jobs on EMR and dynamic scaling of MWAA, you can achieve cost savings by only using resources when needed. This pay-as-you-go model eliminates the need for over-provisioning clusters, reducing operational costs.
Simplicity: The combination of EMR serverless and MWAA eliminates much of the complexity associated with cluster provisioning and management. This simplicity allows data engineers and analysts to focus more on data processing logic and less on infrastructure concerns.
Scalability: Both EMR and MWAA are designed to scale seamlessly based on workload demands. As your data processing requirements grow, you can trust that the underlying infrastructure will adapt accordingly.
Workflow Orchestration: MWAA’s integration with Apache Airflow provides a robust framework for building, scheduling and monitoring complex data workflows. This orchestration capability ensures that your EMR serverless PySpark jobs are executed in a structured and controlled manner.
Conclusion
In this post we have discussed how to integrate PySpark and EMR serverless schedules in MWAA.The combination of Amazon EMR serverless PySpark jobs and Amazon MWAA for workflow orchestration offers a powerful solution for processing and analysing big data in a flexible, scalable and cost-effective manner. This duo empowers organisations to focus on extracting valuable insights from their data without the hassle of infrastructure management.
Note: This article was originally published on Cevo Australia’s website
If you enjoy the article, Please Subscribe.