Apache Iceberg Architecture - Create Iceberg Tables with DDL & CloudFormation

Introduction:
Apache Iceberg has gained significant traction in the big data world due to its robust features, including ACID transactions, schema evolution, and efficient data management.
In this blog we will discuss into the architecture of Apache Iceberg, exploring how it outperforms traditional Hive tables. Additionally, we’ll provide insights into the creation of Iceberg tables using DDL (Data Definition Language) and CloudFormation templates in Athena. Join us as we uncover the efficiency and versatility of Apache Iceberg in modern data environments.
What is a table format?
Its a structured arrangement of data in rows and columns format makes the data to easily readable.
What is the Apache Iceberg?
Netflix created the open-source Iceberg data lake table format, which offers quick and scalable analytics on huge datasets kept in cloud object storage like Microsoft Azure Blob Storage, Amazon S3, and Google Cloud Storage. Built on top of Apache Parquet, it offers powerful indexing algorithms and metadata management to optimize queries and boost performance, as well as support for a variety of data types and serialization formats.
A high-performance format for large analytical tables is called Iceberg. Iceberg enables engines such as Spark, Trino, Flink, Presto, Hive, and Impala to safely work with the same tables simultaneously, while also bringing the simplicity and dependability of SQL tables to the big data space.
Iceberg Architecture:
 Architecture
Architecture
Netflix created the open-source Iceberg data lake table format, which offers quick and scalable analytics on huge datasets kept in cloud object storage like Microsoft Azure Blob Storage, Amazon S3, and Google Cloud Storage. Built on top of Apache Parquet, it offers powerful indexing algorithms and metadata management to optimize queries and boost performance, as well as support for a variety of data types and serialization formats.
A high-performance format for large analytical tables is called Iceberg. Iceberg enables engines such as Spark, Trino, Flink, Presto, Hive, and Impala to safely work with the same tables simultaneously, while also bringing the simplicity and dependability of SQL tables to the big data space.
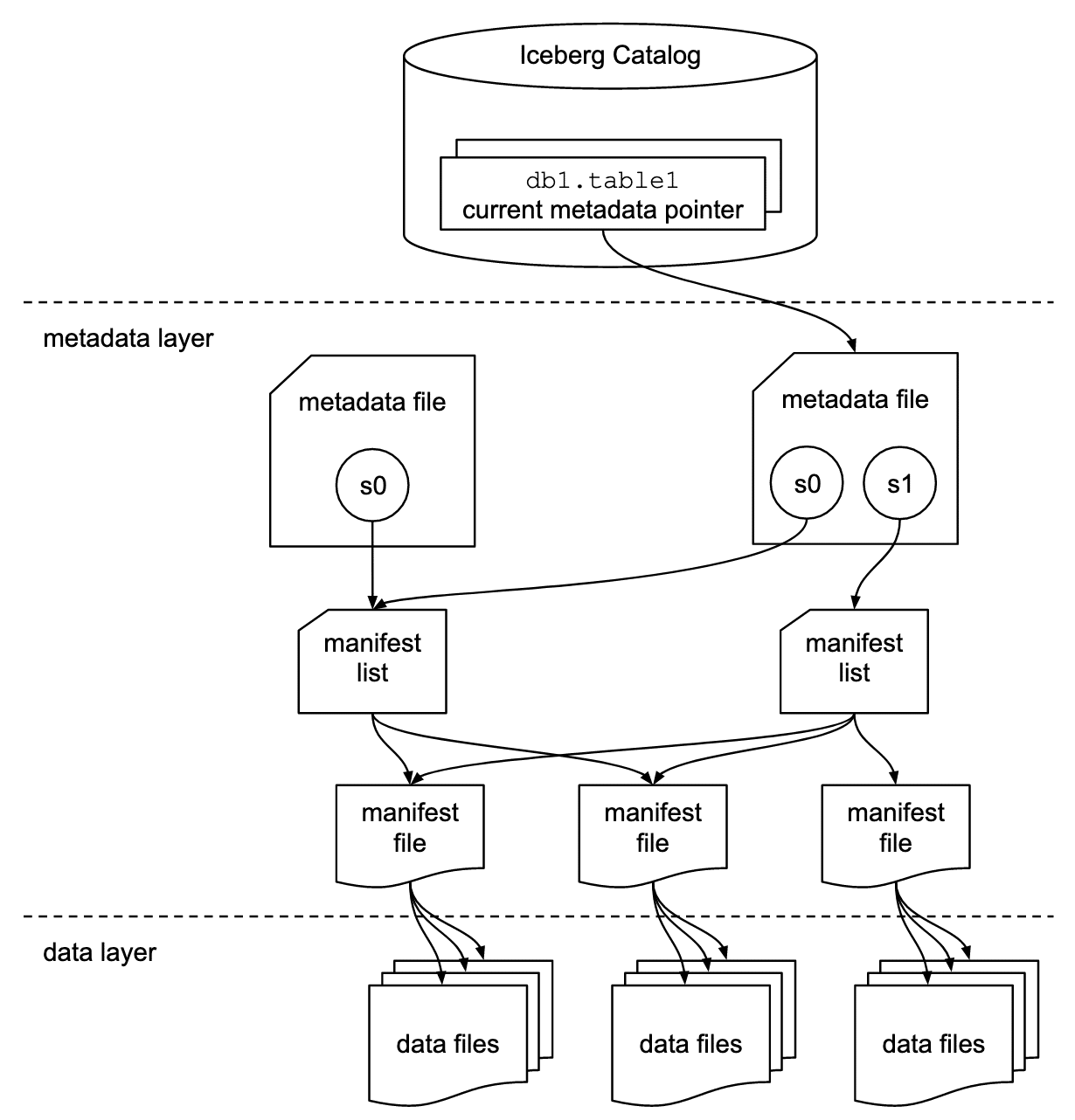
There are 3 layers in the architecture of an Iceberg table:
1) Iceberg catalog
2) Metadata layer, which contains metadata files, manifest lists, and manifest files
3) Data layer
Iceberg catalog This central place where you go to find the current location of the current metadata pointer is the Iceberg catalog.
Metadata file Metadata files store metadata about a table. This includes information about the table’s schema, partition information, snapshots, and which snapshot is the current one.
Manifest list A list of manifest files is called the manifest list. Each manifest file that comprises that snapshot is listed in the manifest list along with details about it, including its location, the snapshot it was added to, the partitions it is a part of, and the lower and upper bounds for the partition columns of the data files it tracks.
Manifest file Each manifest file keeps track of a subset of the data files for parallelism and reuse efficiency at scale. They contain a lot of useful information that is used to improve efficiency and performance while reading the data from these data files, such as details about partition membership, record count, and lower and upper bounds of columns. These statistics are written for each manifest’s subset of data files during write operation, and are therefore more likely to exist, be accurate, and be up to date than statistics in Hive.
Iceberg is file-format agnostic, so the manifest files also specify the file format of the data file, such as Parquet, ORC, or Avro.
Why is the Apache Iceberg so famous, Here is a quick comparison between Hive Table format and the Apache Iceberg Table format
Evolution of Schemas: How Hive and Iceberg handle schema evolution is one of their main distinctions. When the schema changes, Hive demands that the entire dataset be updated, which can be costly and time-consuming. Conversely, Iceberg supports both schema-on-read and schema-on-write techniques and enables more thorough schema evolution, including the addition or removal of columns.
ACID Compliance: Hive does not enable ACID-compliant transactions, hence data consistency and integrity cannot be guaranteed for transactions. Conversely, Iceberg offers transactions that are consistent with ACID standards, meaning that data consistency and integrity are ensured for all transactions.
Updates and Deletes: Hive’s inability to handle efficient updates and deletes might result in longer query times and more expensive storage. Conversely, Iceberg offers effective deletes and updates that can lower query latency and data storage expenses.
Support for cloud storage: Iceberg is designed to work with cloud object stores such as Azure, Google Cloud Storage, and S3. Cloud storage can also be utilized with Hive, albeit additional manual setup may be necessary.
Dynamic Partitioning: Hive partitions data manually, which can be laborious and prone to mistakes. Iceberg allows for dynamic partitioning, which allows any column to be used to partition data—not only the ones listed in the table definition.
Apache Iceberg surpasses Hive in several key aspects, including storage overhead and query performance.
Although they have different designs and use cases, Iceberg and Hive are both effective tools for storing and querying big databases. A well-developed data warehouse solution, Hive has an interface similar to SQL and is designed for batch processing and data warehousing. It is appropriate for businesses that want a recognizable SQL interface. For quick and scalable analytics on cloud object stores, a new data lake table type called Iceberg was created. It works well for businesses that need a scalable and adaptable solution for instantly storing and evaluating big datasets. The particular needs of your use case will determine which option is best.
Glue Catalog
Iceberg enables the use of AWS Glue as the Catalog implementation. When used, an Iceberg namespace is stored as a Glue Database, an Iceberg table is stored as a Glue Table, and every Iceberg table version is stored as a Glue TableVersion. You can start using Glue catalog by specifying the catalog-impl as org.apache.iceberg.aws.glue.GlueCatalog or by setting type as glue
Create Iceberg Table on Glue Database -Using Cloud Formation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
GlueTargeticebergDatabase:
Type: String
Default: iceberg_dataplatform
Resources:
GlueicebergDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: 'iceberg_dataplatform'
Description: 'Target Iceberg table type Athena database'
TableBucket:
Type: 'AWS::S3::Bucket'
Properties:
BucketName: iiceberg-table-location
AccessControl: Private
VersioningConfiguration:
Status: Enabled
Tags:
- Key: CreatedBy
Value: dataplatform-project
StudentData:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref GlueicebergDatabase
TableInput:
Name: "student_data"
StorageDescriptor:
Columns:
- Name: "student_id"
Type: "string"
- Name: "first_name"
Type: "string"
- Name: "last_name"
Type: "string"
- Name: "date_of_birth"
Type: "string"
- Name: "grade_level"
Type: "string"
- Name: "gpa"
Type: "string"
- Name: "favorite_subject"
Type: "string"
- Name: "is_active"
Type: "string"
- Name: "awards"
Type: "string"
Location: !Sub "s3://${TableBucket}/table_data/student_data"
TableType: "EXTERNAL_TABLE"
OpenTableFormatInput:
IcebergInput:
MetadataOperation: "CREATE"
Version: "2"
Create Iceberg table using DDL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
CREATE TABLE iceberg_dataplatform.staff_data (
student_id string,
first_name string,
last_name string,
date_of_birth string,
load_date date)
PARTITIONED BY (MONTH(load_date))
LOCATION 's3://iiceberg-table-location/table_data/staff_data'
TBLPROPERTIES (
'table_type'='iceberg'
);
Once the table has been created a folder will be created in the S3 bucket
Metadata Folder
Once the record has been inserted in the table using athena ,the data folder will be available
Insert a sample record in the iceberg Table
1
2
3
4
5
6
7
8
INSERT INTO iceberg_dataplatform.staff_data
VALUES
('1001', 'John', 'Doe', '1990-05-15', cast('2024-04-20' as date));
INSERT INTO iceberg_dataplatform.staff_data
VALUES
('1001', 'John', 'Doe', '1990-05-15', cast('2024-05-20' as date));
Since We have partitoned the table using month there will be a newfolder will be created in the S3 bucket for fast retrival of data.
Partition for month April
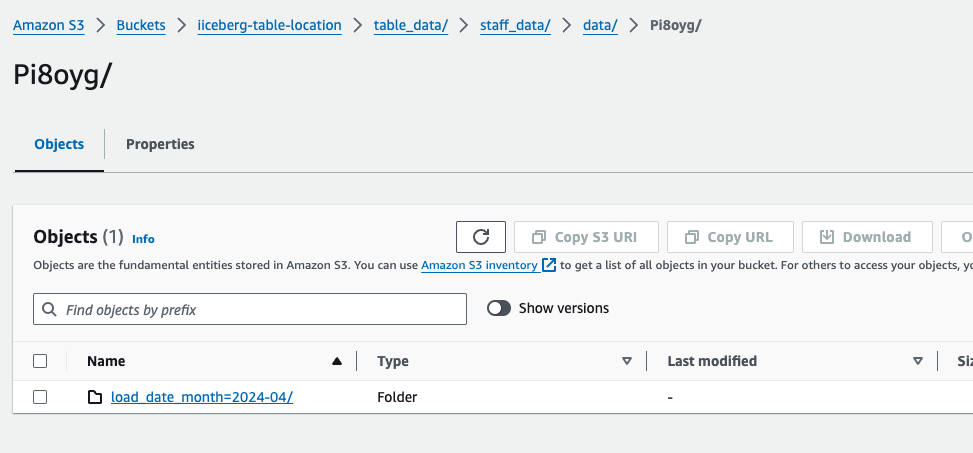 Partition April Month
Partition April Month
Partition for month May
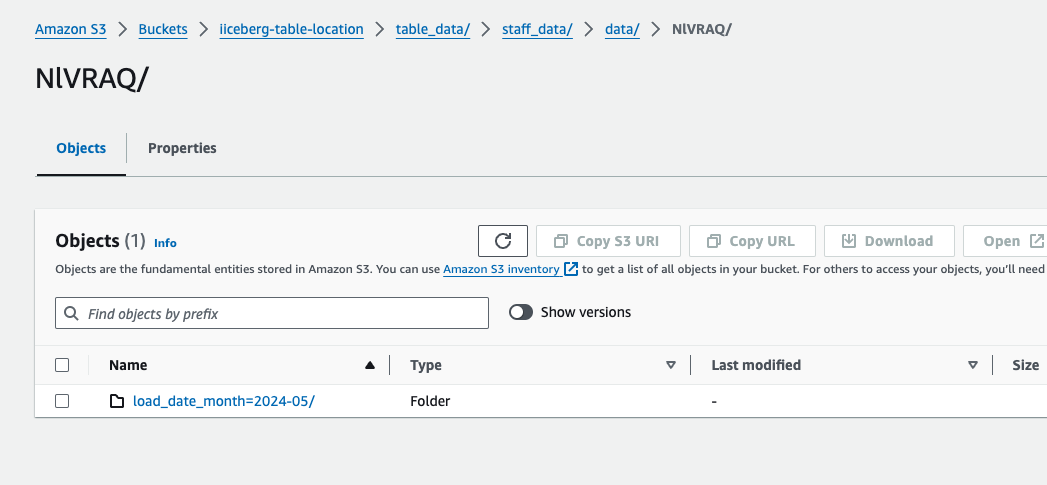 Partition May Month
Partition May Month
Time Travel
In Apache Iceberg, time travel is the ability to query data as it was at a certain moment in time. For the purposes of auditing, debugging, and historical analysis, this capability is quite helpful. By using time travel, you can examine how the data appeared at a previous timestamp by querying a table as if it were in a particular historical condition.
Example:
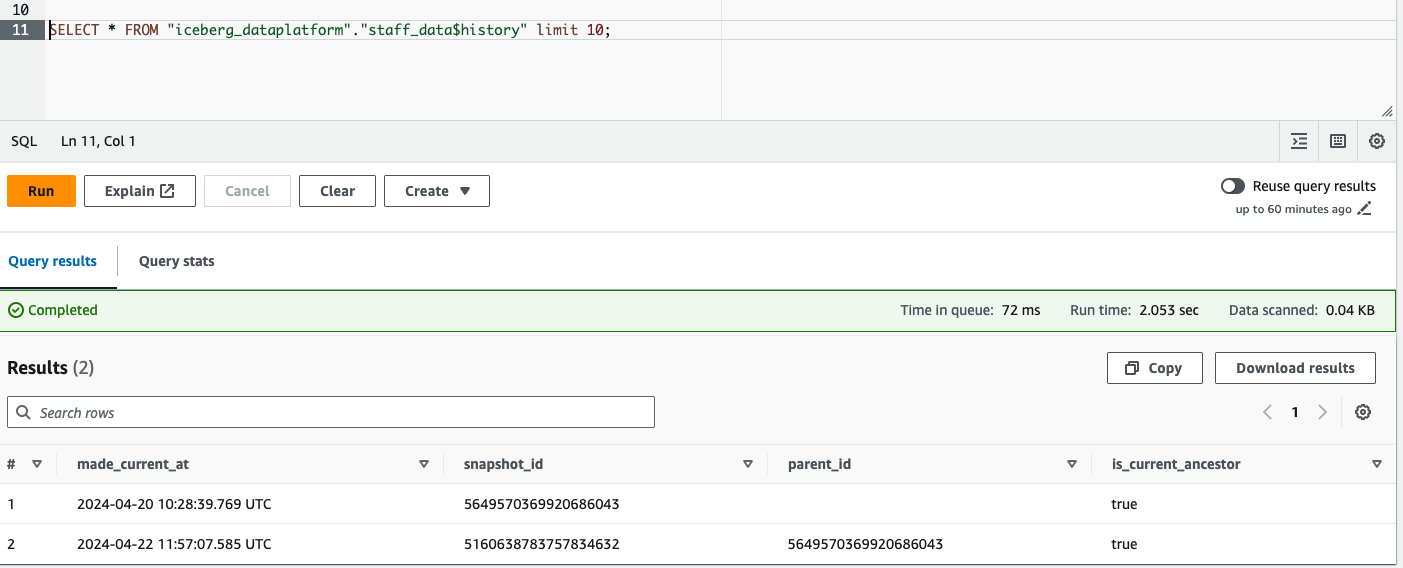 To Query the History
To Query the History
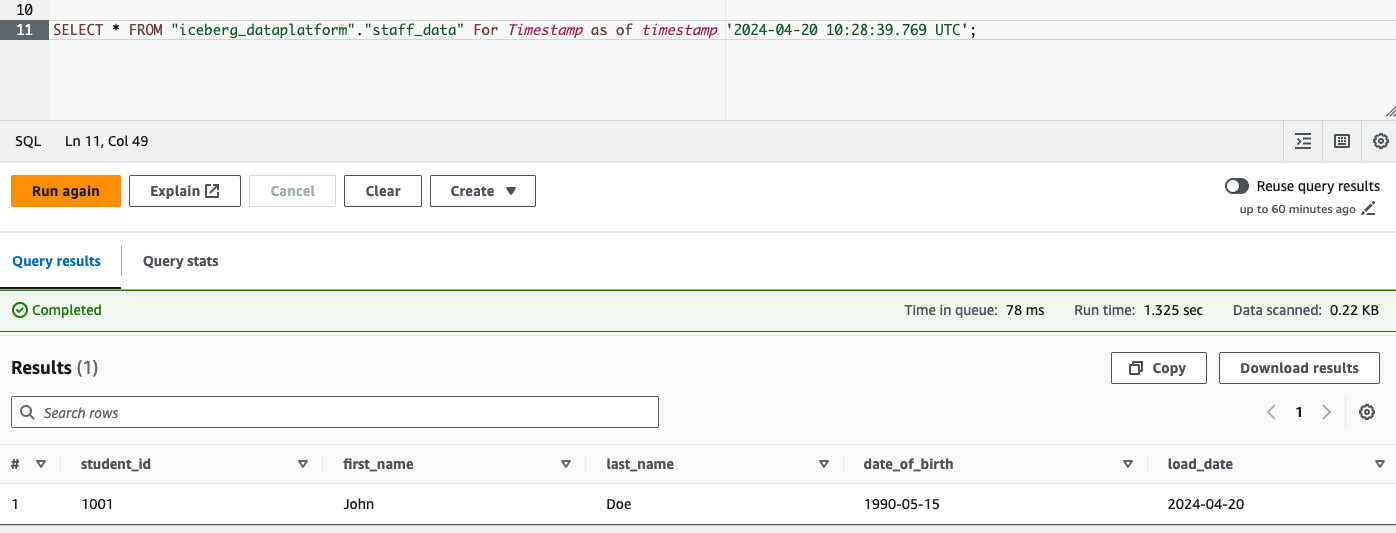 To go back to Time
To go back to Time
Conclusion
In conclusion, Apache Iceberg stands out as a powerful solution for managing big data in modern environments, offering a plethora of advantages over traditional Hive tables. In this blog we have seen how we can create the table using cloudformation/DDL
If you enjoy the article, Please Subscribe.