Efficient XML Data Processing and Querying with AWS Glue and Athena - A Comprehensive Guide
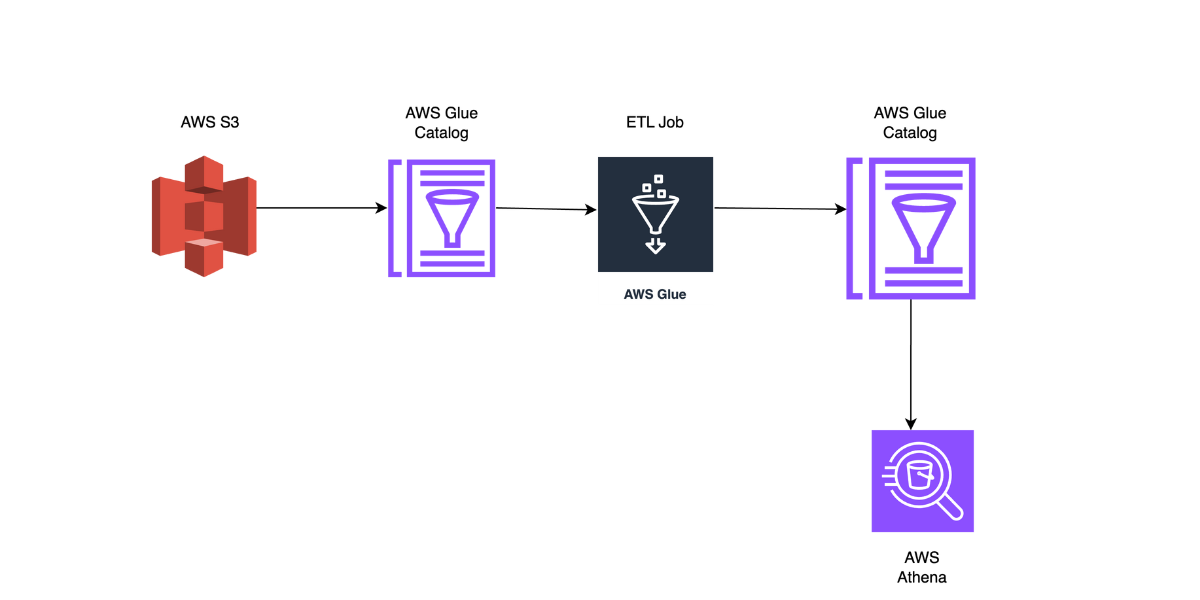
Introduction
In today’s data-driven landscape, the analysis of XML files holds significant importance across diverse industries such as finance, healthcare, and government. The utilization of XML data facilitates organizations in gaining valuable insights, enhancing decision-making processes, and streamlining data integration efforts. However, the semi-structured and highly nested nature of XML files presents challenges in accessing and analyzing information, particularly in the case of large and complex schemas.
In this blog, we will delve into the process of reading XML files in a tabular format using Amazon Athena, leveraging AWS Glue for cataloging, classification, and Parquet-based processing. This comprehensive guide will provide insights into effectively handling XML data within the AWS environment, enabling seamless querying and analysis using Athena.
Prerequisites
Before you begin this tutorial, complete the following prerequisites:
- Download the sample files from kaggle site
- Establish an S3 Bucket and upload the sample files to it.
- Set up all the essential IAM roles and policies.
- Generate an AWS Database utilizing Glue.
Steps to processs the XML file
(i) Before creating a crawler we need to create an xml classifier where we define the rowtag
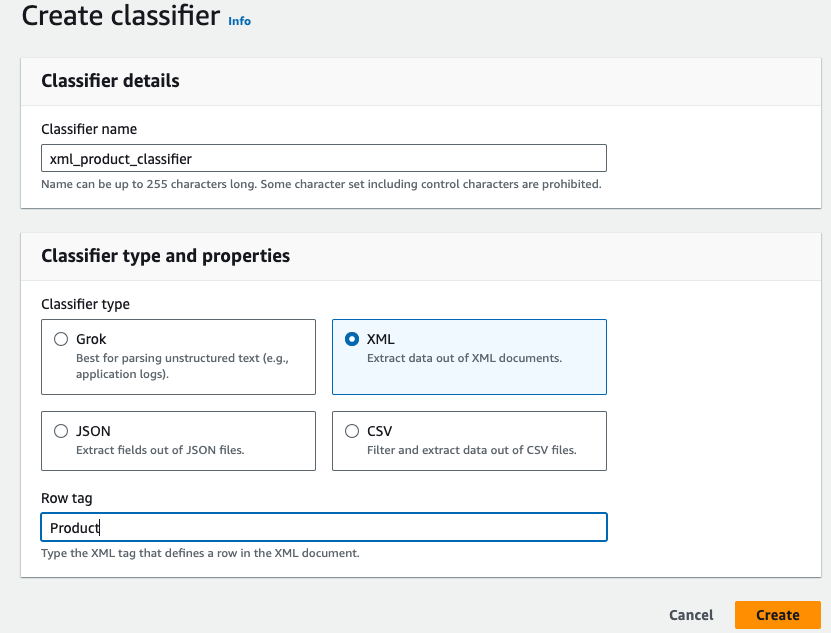 AWS Classifier
AWS Classifier
(ii) Generate an AWS Glue crawler to extract metadata from XML files, then execute the crawler to generate a table in the AWS Glue Data Catalog.
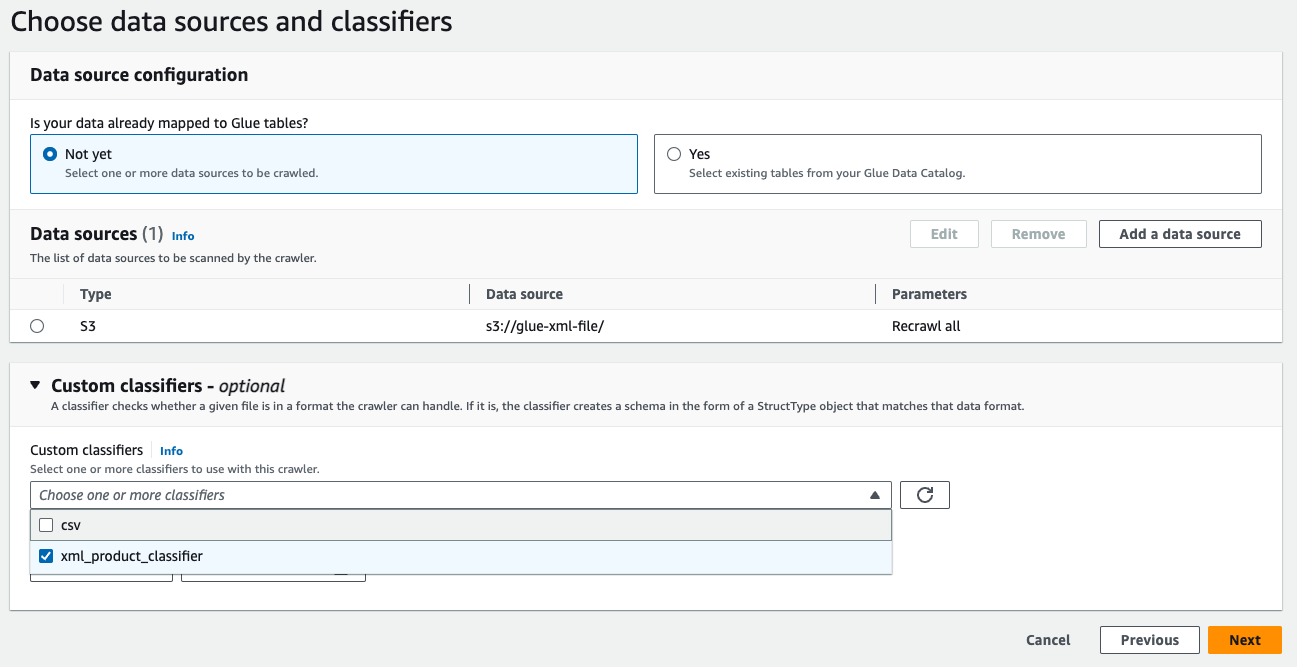 AWS Glue Catalog
AWS Glue Catalog
AWS Glue Database
(iii) Go to Athena to view the table and query it
If we try to query the XML table the query will be failed since Athena wont support XML format
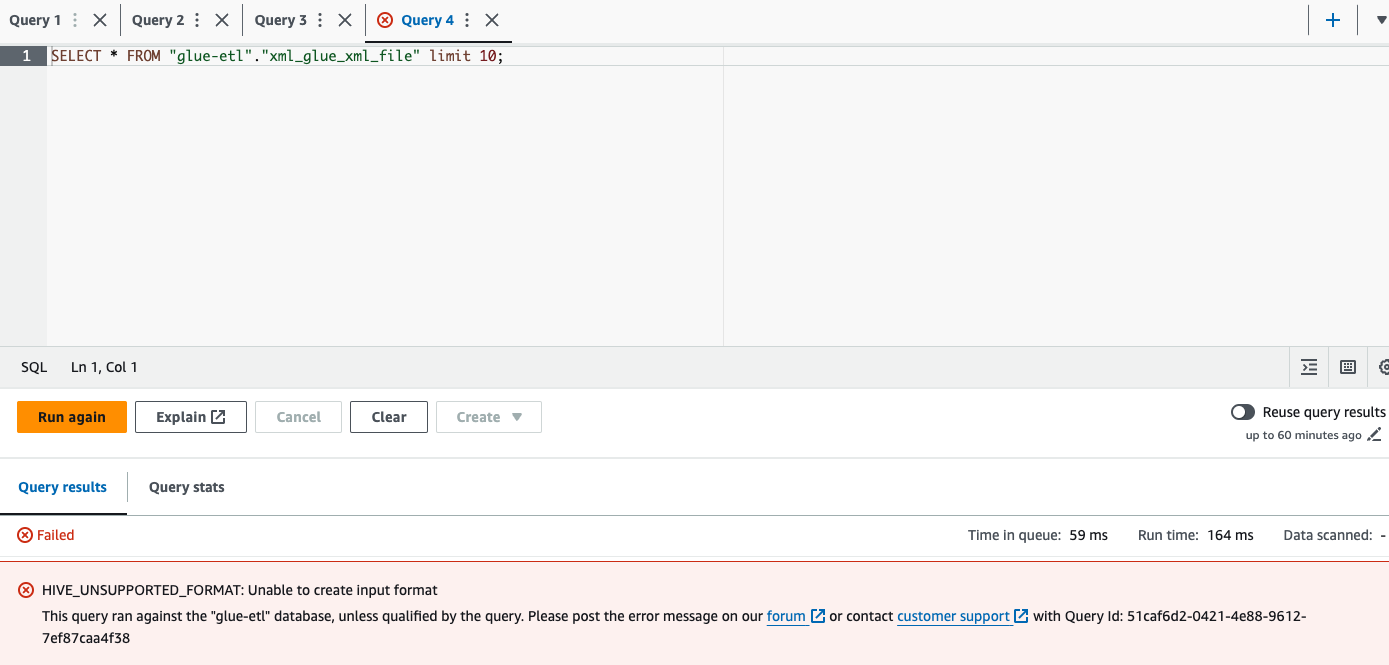 Query XML Table Athena
Query XML Table Athena
(iv) Generate a Glue job to convert XML files to the Parquet format, which can be accomplished using two different methods. Method 1- Use Visual editor from Glue anc convert from XML to Parquet format Method 2 - Use script editor and write the script. In this example I have used pyspark
Method 1:
Step 1 : Go to AWS Glue and select ETL Jobs -> Visual ETL
Step 2 : Choose AWS Glue Data Catalog as Source and select your respective table as below 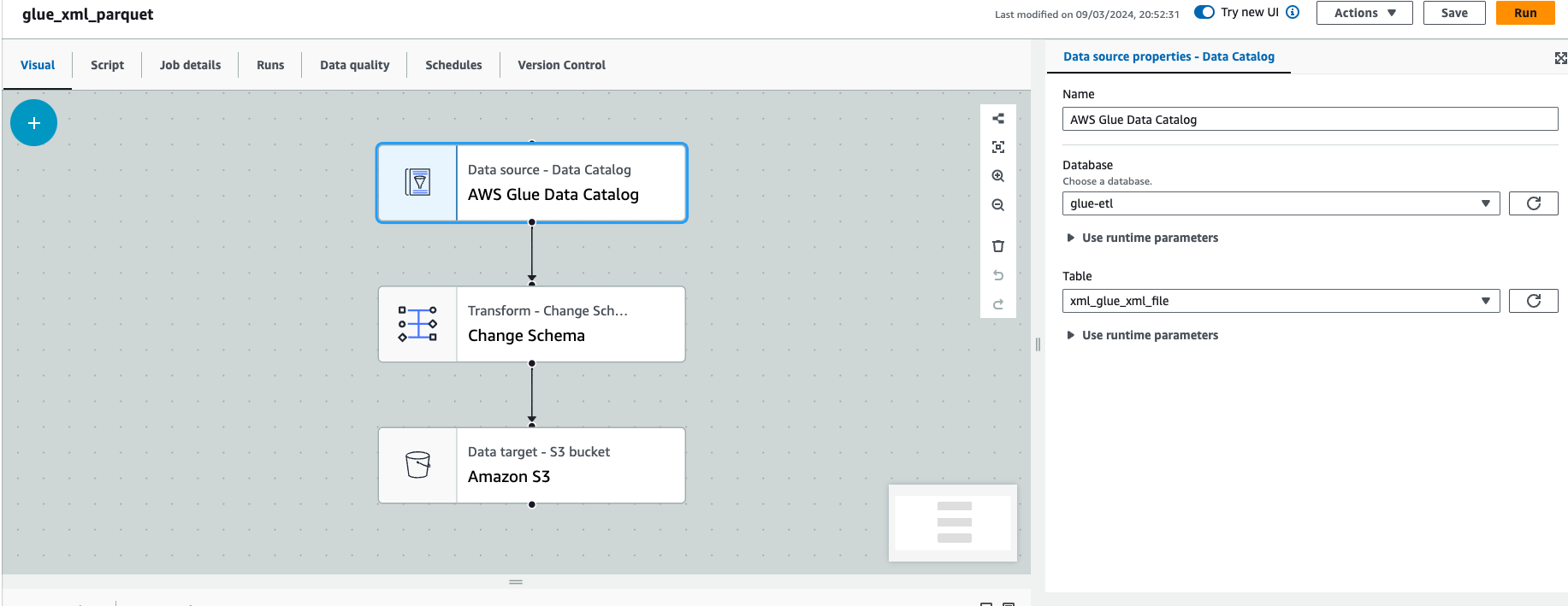 Glue Visual Editor Source
Glue Visual Editor Source
Step 3 : Under transformation choose Change Schema.
Step 4 : Under target select S3 bucket ,parquet format and snappy compression as below 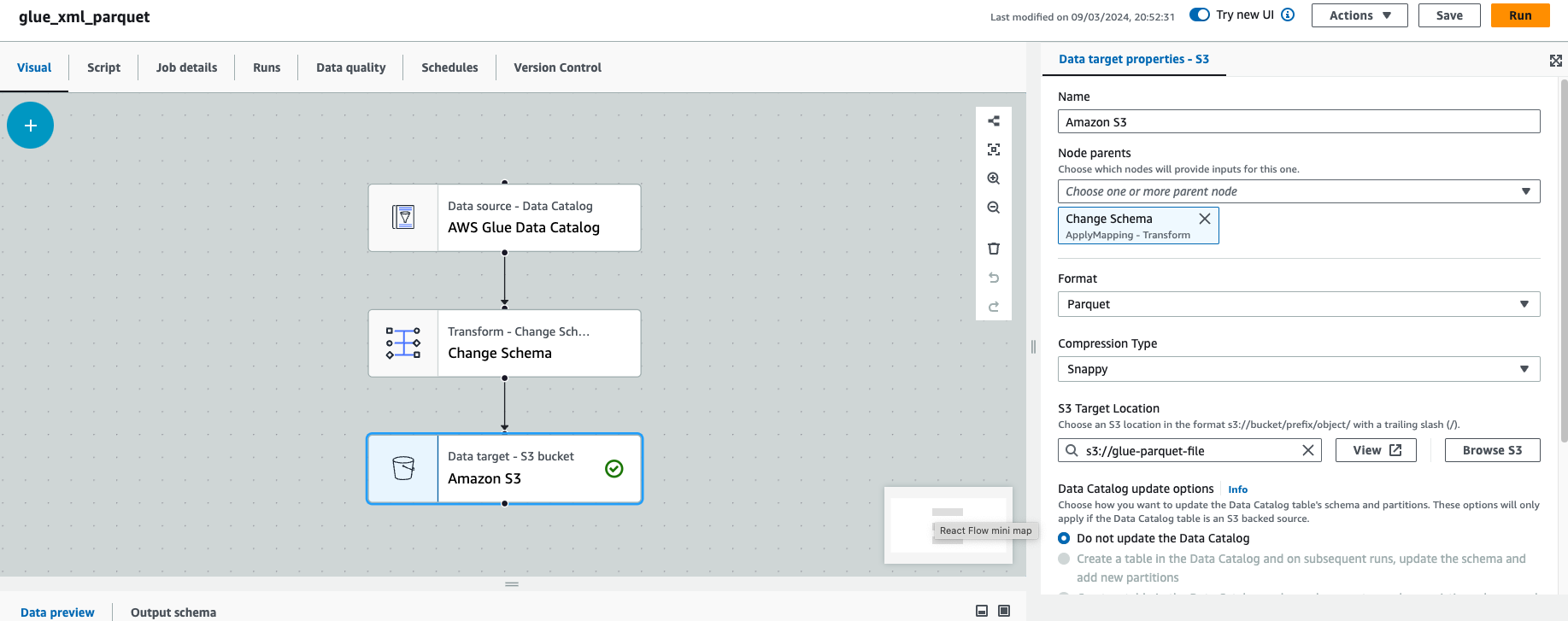 Glue Visual Editor Target
Glue Visual Editor Target
Step 5 : Choose the respective IAM Role and Run the Glue Job
Method 2:
Step 1 : Go to AWS Glue and select ETL Jobs -> Visual ETL -> Script editor
Step 2 : Copy paste the below code and run the job
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
# Initialize GlueContext
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
# Define input and output paths
input_path = "s3://glue-xml-file/"
output_path = "s3://glue-parquet-file/"
# Read XML data as DynamicFrame
xml_dynamic_frame = glueContext.create_dynamic_frame.from_catalog(database = "glue-etl", table_name = "xml_glue_xml_file")
# Convert specific data types to string using Spark SQL functions
xml_dynamic_frame_df = xml_dynamic_frame.toDF()
# Write data to Parquet format
glueContext.write_dynamic_frame.from_options(frame = DynamicFrame.fromDF(xml_dynamic_frame_df, glueContext, "transformed_df"), connection_type = "s3", connection_options = {"path": output_path}, format = "parquet",mode="overwrite")
# Commit the job
job.commit()(v) Create an AWS Glue crawler to extract Parquet metadata and run the crawler which will create a table in the AWS Glue Data Catalog (Choose the same classifier that we created in the first steps)
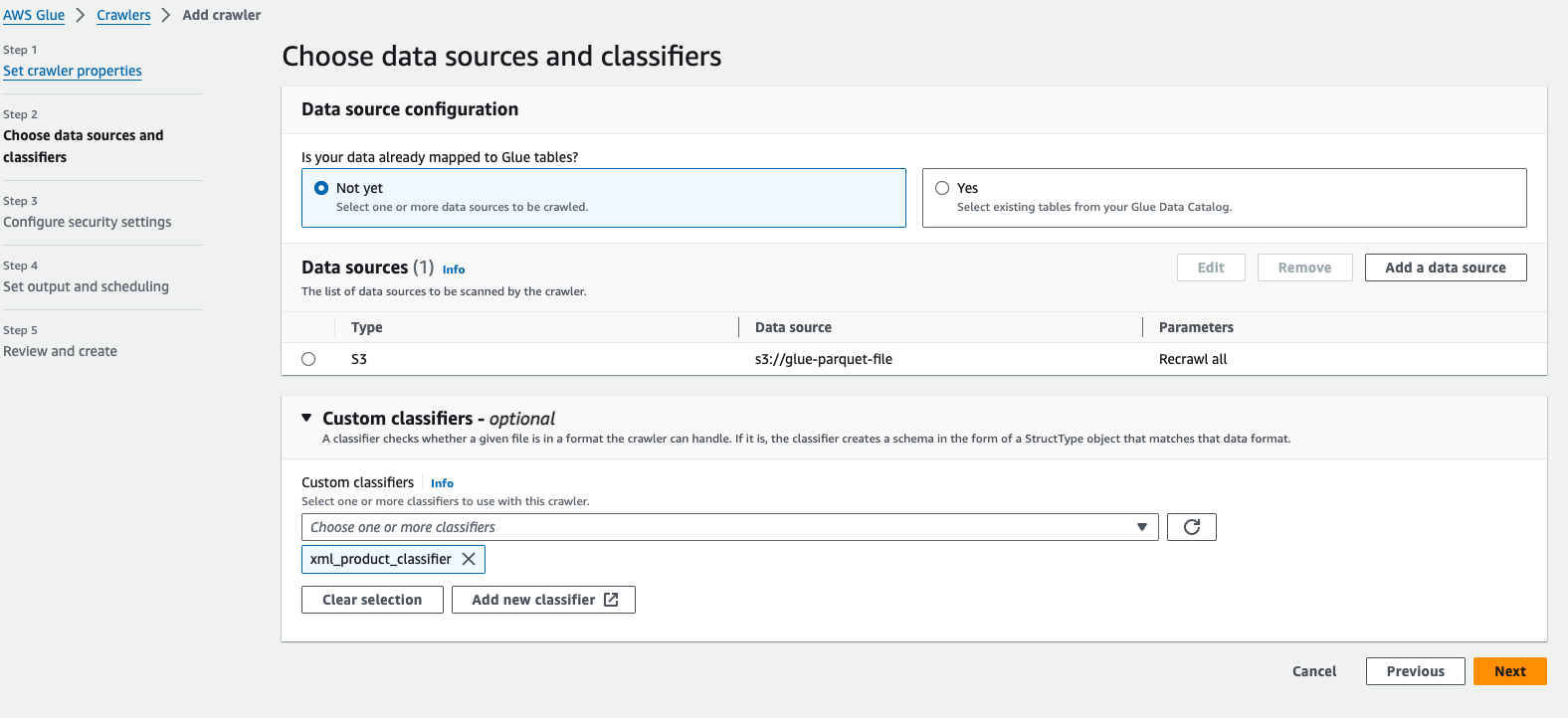 AWS Crawler Parquet Source
AWS Crawler Parquet Source
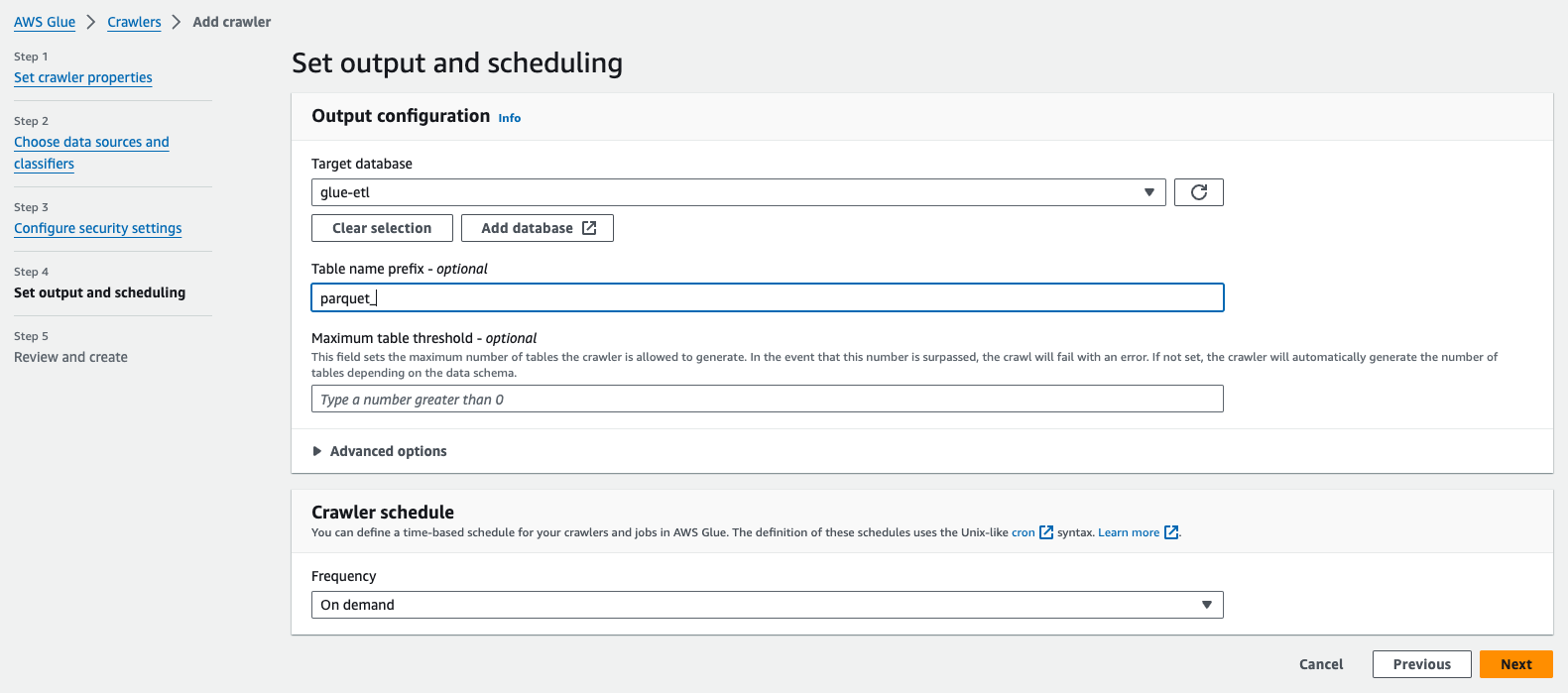 AWS Crawler Parquet Output
AWS Crawler Parquet Output
(vi) Query the table in Athena and the result will be in the JSON format
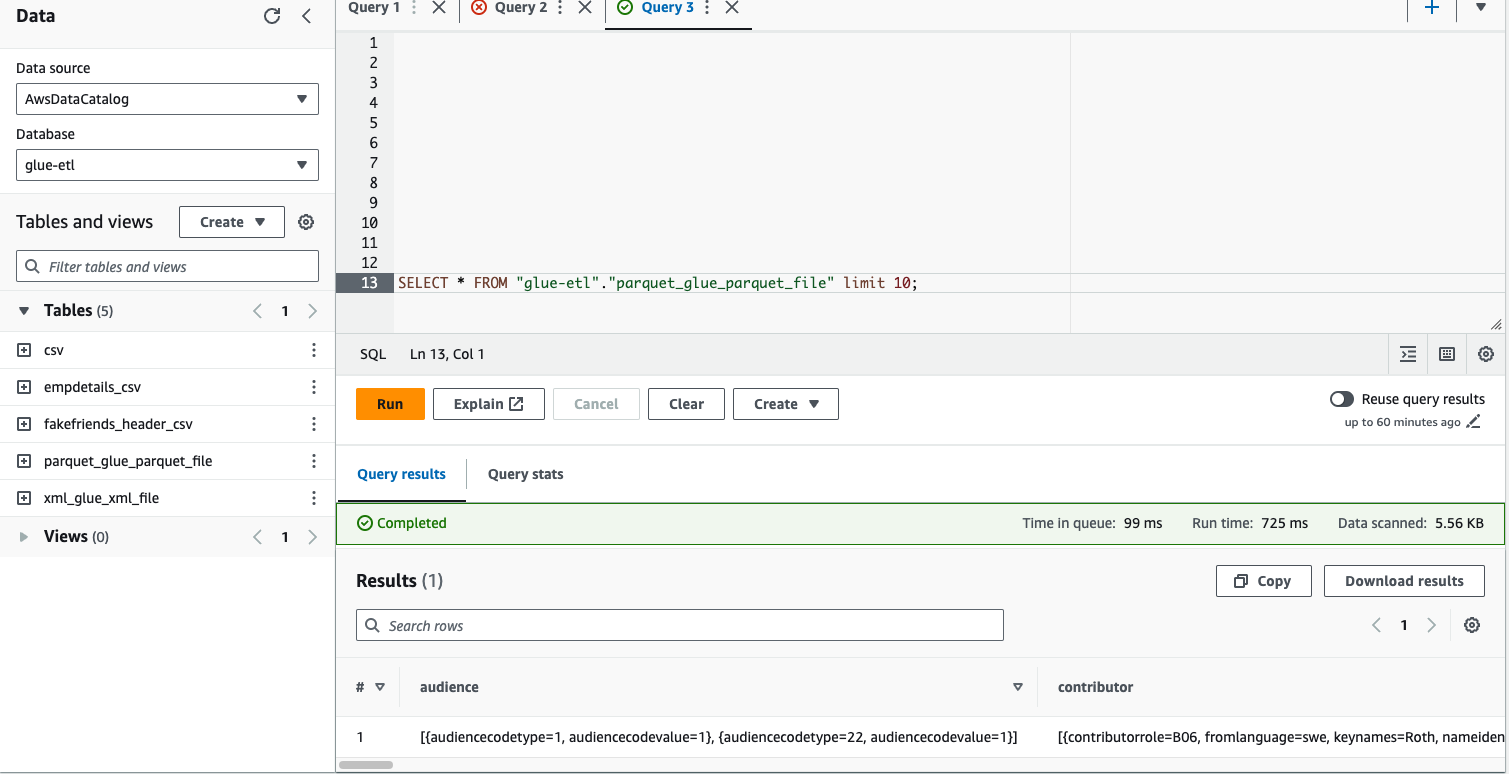 Query Parquet Table Using Athena
Query Parquet Table Using Athena
(vii) To display the JSON data in a tabular format, we must unnest the column. It is essential to grasp the table’s schema before proceeding with the unnesting process.
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder \
.appName("Read Parquet File from S3") \
.getOrCreate()
# S3 path where the Parquet file is located
s3_path = "s3a://glue-parquet-file/"
# Read the Parquet file into a DataFrame
df = spark.read.parquet(s3_path)
# Print the schema of the DataFrame
df.printSchema()
# Stop the SparkSession
spark.stop()Schema Structure of the Table
 Schema Structure Of Parquet Table
Schema Structure Of Parquet Table
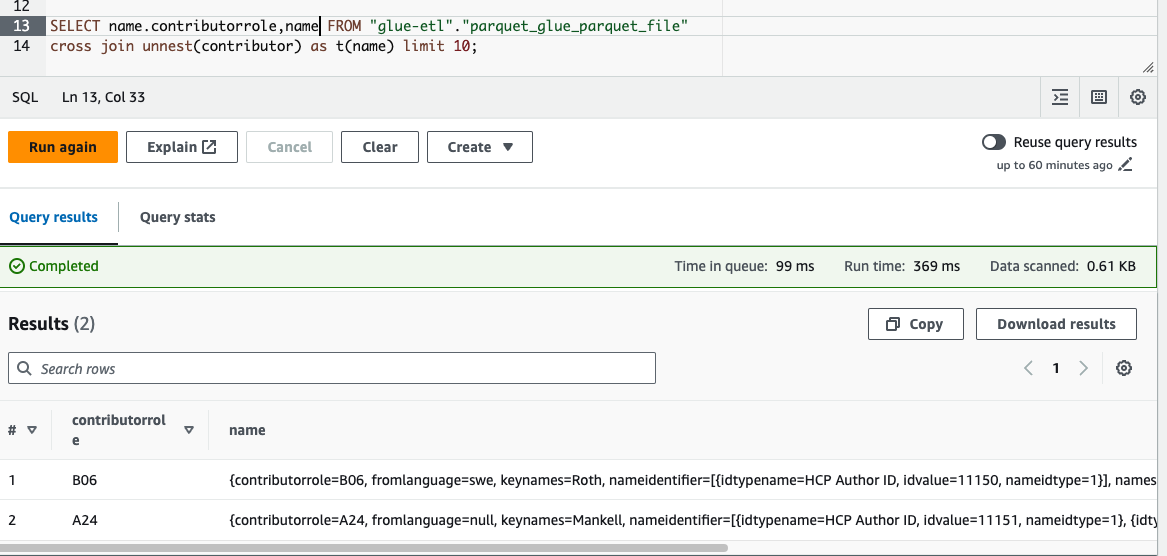 Unnesting the Table using SQL
Unnesting the Table using SQL
To query the table with nested structure
SELECT
con.contributorrole,
nid.idtypename,
con
FROM
"glue-etl"."parquet_glue_parquet_file"
CROSS JOIN
UNNEST(contributor) AS t(con)
CROSS JOIN
UNNEST(con.NameIdentifier) AS t(nid);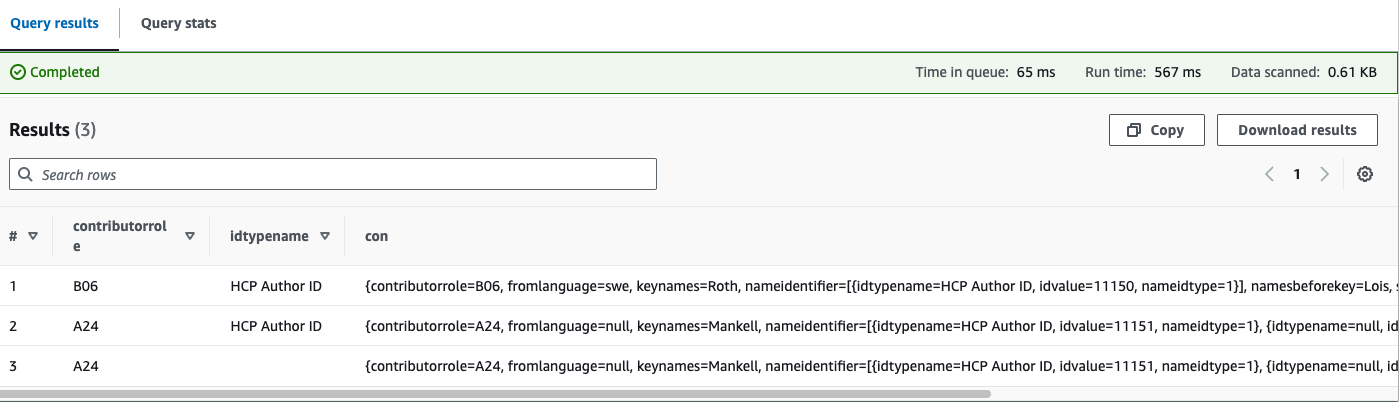 Unnesting the nested Table using SQL
Unnesting the nested Table using SQL
Conclusion
In this article, we have explored the process of reading an XML file using Athena and flattening the table structure for easier analysis. This approach enables users to validate the source data prior to further processing. In our next publication, we will delve into the detailed steps involved in processing XML files using AWS Glue, enhancing the understanding and utilization of these powerful AWS services.
If you enjoy the article, Please Subscribe.