Streamline Onix 3.0 Multi-Nested XML Processing - AWS Glue with DynamicFrames, Relationalize, and Databricks Spark-XML
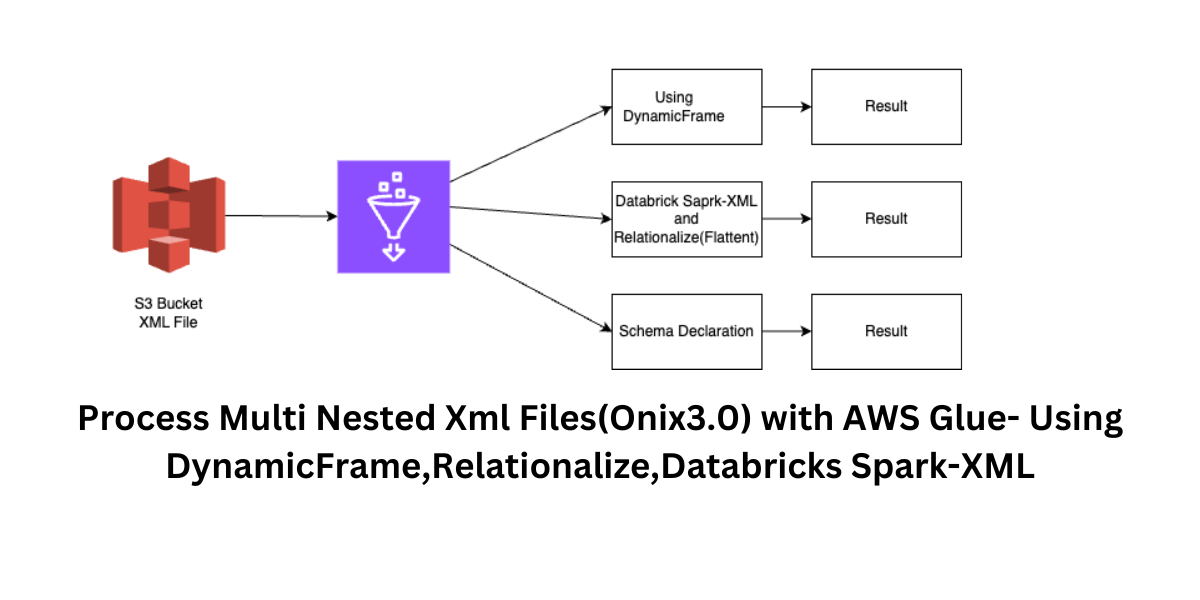
Introduction:
Nowadays, XML files are the go-to option for many industries, including finance, books, and healthcare, for storing and exchanging data. Though XML files are widely used, analyzing and processing them can be difficult, particularly when dealing with highly nested schemas, various nested data structures, and dynamic changes in data types (also known as schema evolution).
In this blog post, we’ll explore how we can address these challenges using AWS Glue, DynamicFrames, Relationalize, and the Databricks Spark XML.
Solution Overview:
Method 1: By using Aws Glue and Dynamic Frame
To handle XML files, using AWS Glue and DynamicFrame is a common method. We may investigate the data types received from the source, whether they are ArrayType, StructType, or a combination of the two, by reading XML files with DynamicFrame. This approach, however, necessitates closely examining every tag and processing records appropriately. The code gets more complex as the files get bigger and the schema gets more complicated, especially with heavily nested schemas.
Prerequisites
1) Get the sample files from the link. GitRepo. Upload the sample files in the S3 Bucket.
 File Upload in S3
File Upload in S3
2) Launch Glue Studio and choose the Notebook option.
 Glue Notebook
Glue Notebook
3) Here’s a Python code snippet using AWS Glue to read an XML file using DynamicFrame and print its schema structure:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql import SparkSession
from awsglue.dynamicframe import DynamicFrame
from datetime import datetime
from pyspark.sql import functions as F
from pyspark.sql.functions import col, slice, size, when, array_contains, to_date, lit, broadcast, split, udf,explode
from pyspark.sql.types import BooleanType
args = {'JOB_NAME':'book-test', 'database_name':'iceberg_dataplatform', 'input_path':'s3://glue-xml-file/bookdetail/3', 'output_path':'s3://glue-xml-file/warehouse/output'}
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
input_path = args['input_path']
output_path = args['output_path']
database_name = args['database_name']
catalog_name = "glue_catalog"
warehouse_path = f"s3://glue-xml-file/warehouse/"
glue_temp_storage = f"s3://glue-xml-file/warehouse/GLUE_TMP"
s3path = {"paths": [input_path]}
print(f"Loading data from {s3path}")
#Read the XML File Using Dynamic Frame
product_options = {"rowTag": "Product", "attachFilename": "book_format"}
dynamicFrameProducts = glueContext.create_dynamic_frame.from_options(
connection_type="s3",
connection_options=s3path,
format="xml",
format_options=product_options,
transformation_ctx="dynamicFrameProducts",
)
#convert the dynamic frame to dataframe
product_df = dynamicFrameProducts.toDF()
#print the schema
product_df.printSchema()
Schema Output:
The below schema has both Array Type and Struct Type
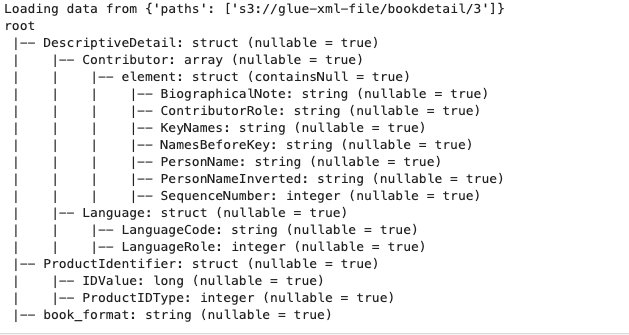 Schema Structure
Schema Structure
After you’ve determined the schema structure, extract the values and display them in a tabular style using the following Python snippet. This simplified method will provide a smooth integration into your intended tables.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# Prepare the Person Name
# Get the Data Type and check if Array or struct Data type
name_type = product_df.schema["DescriptiveDetail"].dataType["Contributor"].dataType
if "array" in name_type.typeName():
print('array')
product_df = product_df.withColumn("name", explode("DescriptiveDetail.Contributor"))
product_df = product_df.withColumn("PersonName", col("name.PersonName"))
elif "struct" in name_type.typeName():
print('struct')
product_df = product_df.withColumn("PersonName", when(col("DescriptiveDetail.Contributor.struct.PersonName").isNotNull(),
col("DescriptiveDetail.Contributor.struct.PersonName")
).otherwise(None))
# Prepare the Language
language_type = product_df.schema["DescriptiveDetail"].dataType["Language"].dataType
if "array" in language_type.typeName():
print('lang array')
product_df = product_df.withColumn("Language", explode("DescriptiveDetail.Language"))
product_df = product_df.withColumn("Language", when (col("Language.LanguageRole") == 1, col("Language.LanguageCode")).otherwise(None))
elif "struct" in language_type.typeName():
print(' lang struct')
product_df = product_df.withColumn("Language", when(col("DescriptiveDetail.Language.LanguageRole") ==1,
col("DescriptiveDetail.Language.LanguageCode")
).otherwise(None))
# Prepare the book_id
product_type = product_df.schema["ProductIdentifier"].dataType
if "array" in product_type.typeName():
print('product array')
product_df = product_df.withColumn("book", explode("ProductIdentifier"))
product_df = product_df.withColumn("book_id",col("book.book_id"))
elif "struct" in product_type.typeName():
print(' product struct')
product_df = product_df.withColumn("book_id", col("ProductIdentifier.IDValue"))
book_df=product_df.select(col("book_id"),col("PersonName"),col("Language")).show()
Result:
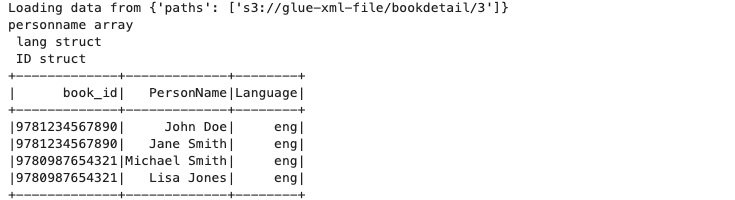 Final Output
Final Output
This method works well even when the schema structure isn’t stated explicitly. However, the coding complexity dramatically rises with the amount of tags and hierarchical schema structures.
Method 2: By using Aws Glue ,Databricks library and Relationalize
Relationalize will flatten the nested structure. While reading the XML files using the DataBricks Spark-Xml, it will provide more precise control over parsing complex XML structures. SampleFile
Prerequisite
1) Download the Databricks Spark-XML JAR File: Obtain the Databricks Spark-XML JAR file from the.MVNRepository
2) Upload the JAR File to an S3 Bucket: Upload the downloaded JAR file to an S3 bucket that your AWS Glue job can access.
 DataBrciks Jar File
DataBrciks Jar File
3) Configure Your AWS Glue Notebook: In the first cell of your AWS Glue notebook, add the following code to ensure that the Databricks Spark-XML library is available to your job
1
2
3
4
5
6
7
8
9
%idle_timeout 30
%glue_version 4.0
%%configure
{
"--extra-jars": "s3://glue-xml-file/jarfile/spark-xml_2.12-0.13.0.jar",
"--conf": "spark.jars.packages=com.databricks:spark-xml_2.12:0.13.0"
}
You can observe how DataBricks Spark-XML reads XML more effectively than dynamicframe work in the example below.
Schema for Dynamic Frame Work
 Dynamic Frame Schema Structure
Dynamic Frame Schema Structure
Schema for Databricks-Spark Xml
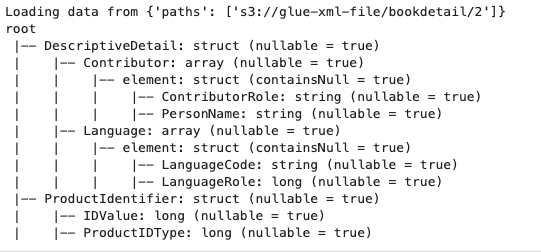 Databrick Schema Structure
Databrick Schema Structure
The below snippet is to read the XML file using DataBrick spark-XML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql import SparkSession
from awsglue.dynamicframe import DynamicFrame
from datetime import datetime
from pyspark.sql import functions as F
from pyspark.sql.functions import col, slice, size, when, array_contains, to_date, lit, broadcast, split, udf,explode
from pyspark.sql.types import BooleanType
args = {'JOB_NAME':'book-test', 'database_name':'iceberg_dataplatform', 'input_path':'s3://glue-xml-file/bookdetail/2', 'output_path':'s3://glue-xml-file/warehouse/output'}
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
input_path = args['input_path']
output_path = args['output_path']
database_name = args['database_name']
catalog_name = "glue_catalog"
warehouse_path = f"s3://glue-xml-file/warehouse/"
xml_input_path = f"{input_path}/"
glue_temp_storage = f"s3://glue-xml-file/warehouse/GLUE_TMP"
s3path = {"paths": [input_path]}
print(f"Loading data from {s3path}")
product_df = spark.read.format('xml').options(rowTag='Product', excludeAttribute=True).load(f'{xml_input_path}')
#product_df = dynamicFrameProducts.toDF()
product_df.printSchema()
The relationalize function will flatten the nested structure, storing it as keys in a tabular format. Utilize the following snippet to achieve the flattening.The relationalize needs the S3 path to store the flattened structure
1
2
3
4
5
6
dyf = DynamicFrame.fromDF(product_df, glueContext, "dyf")
dfc = dyf.relationalize("root", "s3://glue-xml-file/temp-dir/")
dfc.keys()
all_keys = list(dfc.keys())
print(all_keys)
Output
 Relationalize Key
Relationalize Key
Use the below snippet to read the root and the sub keys
1
2
3
4
5
6
7
8
9
10
dyf = DynamicFrame.fromDF(product_df, glueContext, "dyf")
dfc = dyf.relationalize("root", "s3://glue-xml-file/temp-dir/")
dfc.keys()
all_keys = list(dfc.keys())
print(all_keys)
final_df = dfc.select('root')
final_df=final_df.toDF()
final_df.show()
Output
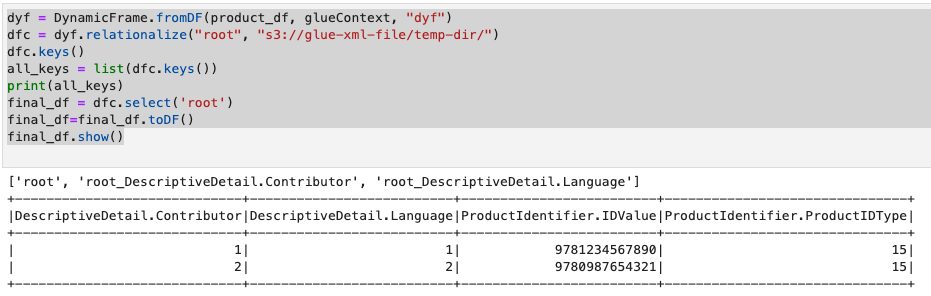 Root Result
Root Result
1
2
3
4
5
6
7
8
9
dyf = DynamicFrame.fromDF(product_df, glueContext, "dyf")
dfc = dyf.relationalize("root", "s3://glue-xml-file/temp-dir/")
dfc.keys()
all_keys = list(dfc.keys())
print(all_keys)
fin_df = dfc.select('root_DescriptiveDetail.Language')
fin_df=fin_df.toDF()
fin_df.show()
Output
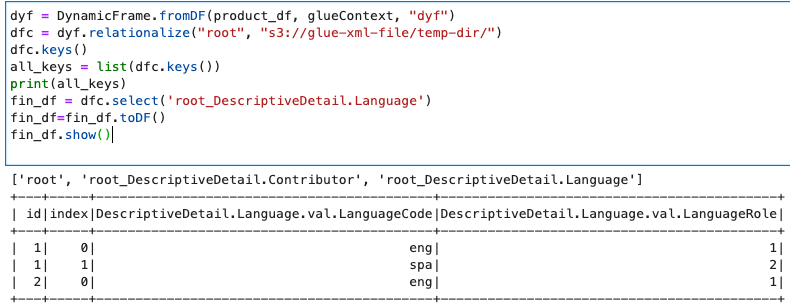 Sub Key Result
Sub Key Result
The next step is to join the root key and the other sub keys. The root key will have the reference identifier in the sub keys table
For example, Root key Identifier “DescriptiveDetail.Language” and the subkey identifier “id”. In the below code, we will be joining the keys to extract of the flattening data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
dyf = DynamicFrame.fromDF(product_df, glueContext, "dyf")
dfc = dyf.relationalize("root", "s3://glue-xml-file/temp-dir/")
dfc.keys()
all_keys = list(dfc.keys())
print(all_keys)
final_df = dfc.select('root')
final_df=final_df.toDF()
fin_df = dfc.select('root_DescriptiveDetail.Language')
fin_df=fin_df.toDF()
fin_df.createOrReplaceTempView(f"language")
final_df.createOrReplaceTempView(f"final_df")
result=spark.sql(""" select * from final_df fd join
language ct on fd.`DescriptiveDetail.Language` =ct.id""")
result.createOrReplaceTempView(f"language")
spark.sql("""select `ProductIdentifier.IDValue` isbn,`DescriptiveDetail.Language.val.LanguageCode` LanguageCode,
`DescriptiveDetail.Language.val.LanguageRole` LanguageRole from language
""").show()
Final Result
 FinalResult
FinalResult
To include the Databricks Spark-XML JAR file in the AWS Glue job, you need to specify the S3 bucket path and provide configuration details in the job parameters as illustrated below.
”–conf”: “spark.jars.packages=com.databricks:spark-xml_2.12:0.13.0”
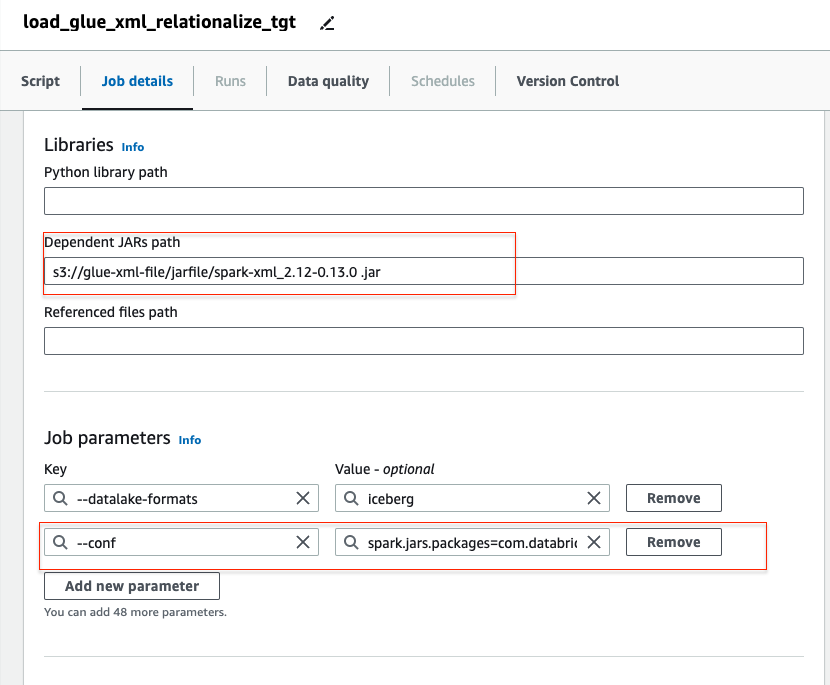 Glue Library
Glue Library
Method 3: Using AWS Glue,Dynamic Frame and Declaring the Schema.
In this approach, we’ll employ the dynamic frame framework to read the XML, wherein we’ll assign the nested schema to the defined schema structure. This allows us to understand the structure beforehand, facilitating the straightforward reading of multi-nested files.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql import SparkSession
from awsglue.dynamicframe import DynamicFrame
from datetime import datetime
from pyspark.sql import functions as F
from pyspark.sql.functions import col, slice, size, when, array_contains, to_date, lit, broadcast, split, udf,explode
from pyspark.sql.types import BooleanType
from pyspark.sql.types import (
StructType,
StructField,
StringType,
IntegerType,
ArrayType
)
from pyspark.sql.functions import col, udf, from_json
args = {'JOB_NAME':'book-test', 'database_name':'iceberg_dataplatform', 'input_path':'s3://glue-xml-file/bookdetail/2', 'output_path':'s3://glue-xml-file/warehouse/output'}
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
input_path = args['input_path']
output_path = args['output_path']
database_name = args['database_name']
catalog_name = "glue_catalog"
warehouse_path = f"s3://glue-xml-file/warehouse/"
glue_temp_storage = f"s3://glue-xml-file/warehouse/GLUE_TMP"
s3path = {"paths": [input_path]}
print(f"Loading data from {s3path}")
spark = SparkSession.builder \
.config("spark.sql.warehouse.dir", warehouse_path) \
.config(f"spark.sql.catalog.{catalog_name}", "org.apache.iceberg.spark.SparkCatalog") \
.config(f"spark.sql.catalog.{catalog_name}.warehouse", warehouse_path) \
.config(f"spark.sql.catalog.{catalog_name}.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog") \
.config(f"spark.sql.catalog.{catalog_name}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.getOrCreate()
product_options = {"rowTag": "Product", "attachFilename": "book_format"}
dynamicFrameProducts = glueContext.create_dynamic_frame.from_options(
connection_type="s3",
connection_options=s3path,
format="xml",
format_options=product_options,
transformation_ctx="dynamicFrameProducts",
)
product_df = dynamicFrameProducts.toDF()
product_df.printSchema()
schema=ArrayType(StructType([StructField('LanguageCode', StringType()),StructField('LanguageRole', StringType())]))
datachoice0 = ResolveChoice.apply(
frame=dynamicFrameProducts,
choice="cast:string",
transformation_ctx="datachoice0",
)
# In string form, look to see if the string is in a square bracket [, indicating an array, if not add them
@udf(returnType=StringType())
def struct_to_array(order):
if order:
return f"[{order}]" if order[:1] != "[" else order
# Handle case where "array" is empty
return "[]"
map0 = datachoice0.toDF().withColumn(
"Language_array", from_json(struct_to_array(col("DescriptiveDetail.Language")),schema)
)
fromdataframe = DynamicFrame.fromDF(map0, glueContext, "fromdataframe0")
fromdataframe=fromdataframe.toDF()
fromdataframe.printSchema()
schema=ArrayType(StructType([StructField('LanguageCode', StringType()),StructField('LanguageRole', StringType())]))
datachoice0 = ResolveChoice.apply(
frame=dynamicFrameProducts,
choice="cast:string",
transformation_ctx="datachoice0",
)
# In string form, look to see if the string is in a square bracket [, indicating an array, if not add them
@udf(returnType=StringType())
def struct_to_array(order):
if order:
return f"[{order}]" if order[:1] != "[" else order
# Handle case where "array" is empty
return "[]"
map0 = datachoice0.toDF().withColumn(
"Language_array", from_json(struct_to_array(col("DescriptiveDetail.Language")),schema)
)
fromdataframe = DynamicFrame.fromDF(map0, glueContext, "fromdataframe0")
product_df=fromdataframe.toDF()
product_df.printSchema()
product_df.createOrReplaceTempView(f"language")
#spark.sql(""" select * from Language""").show()
language_type = product_df.schema["Language_array"].dataType
if "array" in language_type.typeName():
print('lang array')
product_df = product_df.withColumn("Language", explode("Language_array"))
product_df = product_df.withColumn("Language", when (col("Language.LanguageRole") == 1, col("Language.LanguageCode")).otherwise(None))
elif "struct" in language_type.typeName():
print(' lang struct')
product_df = product_df.withColumn("Language", when(col("Language_array.LanguageRole") ==1,
col("Language_array.LanguageCode")
).otherwise(None))
# Prepare the book_id
product_type = product_df.schema["ProductIdentifier"].dataType
if "array" in product_type.typeName():
print('ID array')
product_df = product_df.withColumn("book", explode("ProductIdentifier"))
product_df = product_df.withColumn("book_id",col("book.book_id"))
elif "struct" in product_type.typeName():
print(' ID struct')
product_df = product_df.withColumn("book_id", col("ProductIdentifier.IDValue"))
#product_df.printSchema()
book_df=product_df.select(col("book_id"),col("Language")).show()
Output
 Schema Result
Schema Result
Summary:
This blog extensively explores the efficient methods for reading multi-nested schema structures, including dynamic data type changes, through the utilization of DynamicFrame, Relationalize, Databricks Spark-XML, and schema definition.
Don’t forget to subscribe to the page for updates, and visit the associated GitHub repository where the complete code is available. It showcases how we can dynamically process multiple files simultaneously, each with different data types, using Relationalize.
If you enjoy the article, Please Subscribe.
If you love the article, Please consider supporting me by buying a coffee for $1.
«meta name=”google-adsense-account” content=”ca-pub-4606733459883553”>