Part 1 - Orchestrating Snowflake Data Transformations with DBT on Amazon ECS through Apache Airflow.
Overview:
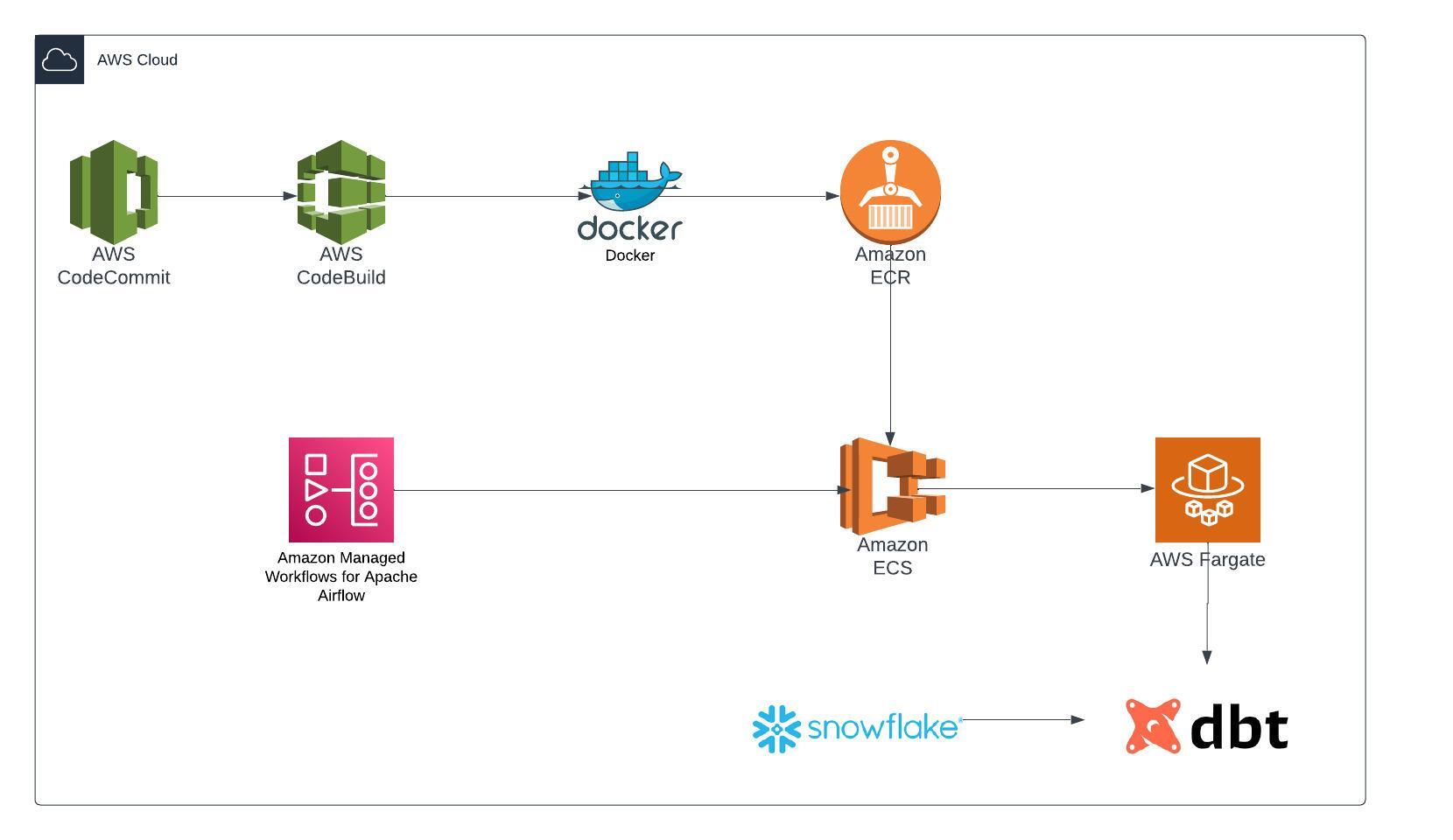
This blog offers a comprehensive walkthrough for setting up DBT to execute data transformation tasks specifically designed for Snowflake. We’ve streamlined the DBT configuration process by packaging it within a Docker Image, which is securely stored in a private ECR repository. To efficiently handle scheduling and orchestration, we’ve harnessed the power of both ECS Service and MWAA. You can access the source code in this GitRepo.
Architecture:
Architecture
Data Build Tool:
Data build tool (DBT) enables analytics engineers to transform data in their warehouses by simply writing select statements. DBT handles turning these select statements into tables and views.
DBT does the T in ELT (Extract, Load, Transform) processes – it doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse.
Infrastructure :
There are various installation methods for DBT, but in our case, where our aim is to deploy DBT as a container on ECS Fargate, the initial step entails Dockerfile preparation.
Docker File:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
# SPDX-License-Identifier: MIT-0
FROM python:3.8-slim-buster
ADD dbt-project /dbt-project
# Update and install system packages
RUN apt-get update -y && \
apt-get install --no-install-recommends -y -q \
git libpq-dev python-dev && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
# Install DBT
RUN pip install -U pip
RUN pip install dbt-core
RUN pip install dbt-snowflake
RUN mkdir -p /root/.dbt
COPY /dbt-project/profiles.yml /root/.dbt/profiles.yml
WORKDIR /dbt-project
#CMD ["/bin/bash"]
#ENTRYPOINT ["dbt","run"]
DBT Project:
A DBT project is a directory of .sql and .yml files, which DBT uses to transform your data. At a minimum, a DBT project must contain:
A project file: A DBT_project.yml file tells DBT that a particular directory is a DBT project, and also contains configurations for your project.
Models: A model is a single .sql file. Each model contains a single select statement that either transforms raw data into a dataset that is ready for analytics, or, more often, is an intermediate step in such a transformation. A project may also contain a number of other resources, such as snapshots, seeds, tests, macros, documentation, and sources.
Source Code:
The source code is housed within the CodeCommit repository. Please find the source code GitRepo. Please find the tree of the source code, as seen below.
1
2
3
4
5
6
7
8
9
10
11
12
13
-Config
-buildspec.yml
-SourceCode
-dbt-project
- dbt_project.yml
- README.md
- tests
- snapshots
- models
- macros
- data
- analysis
-Dockerfile
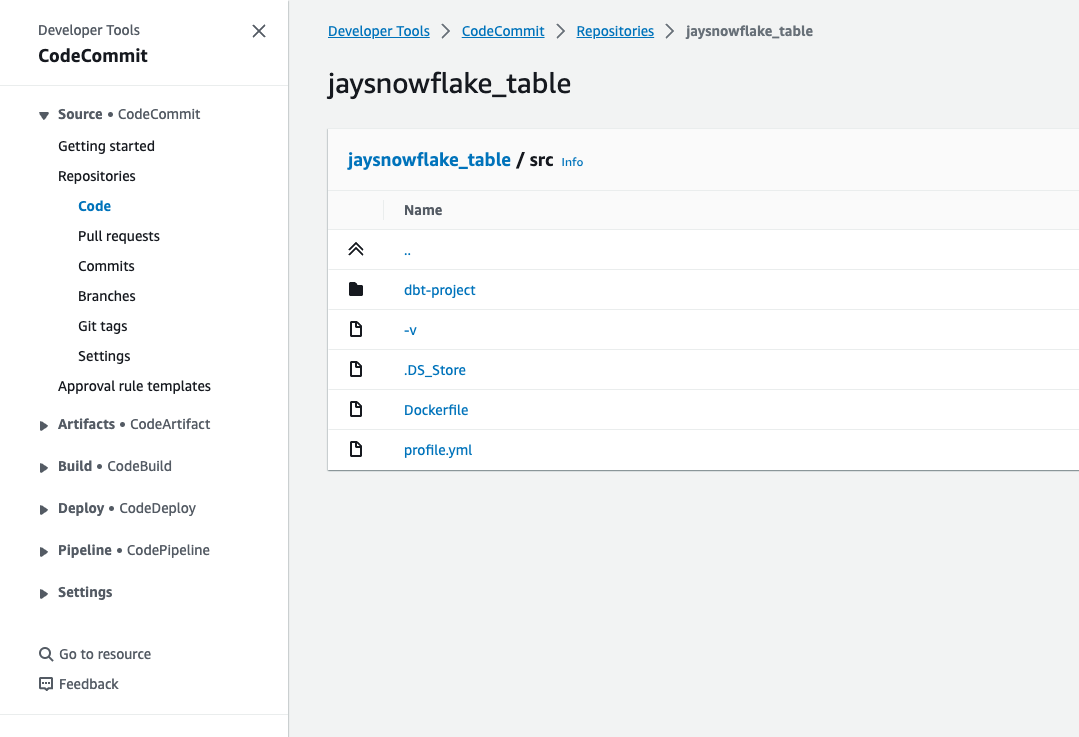 Code Commit Src
Code Commit Src
DBT configuration:
In this instance, we are establishing a connection between the DBT tool and Snowflake. Typically, database connections are retrieved from the profiles.yml file. Meanwhile, sensitive information is dynamically extracted from Secret Manager or Parameter Store during the code building process.
The details we have passed in Code Build as an environmental variable.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
dbtlearn:
target: dev
outputs:
dev:
type: snowflake
account: ********
user: dbt
password: **********
role: transform
database: customer
warehouse: compute_wh
schema: dev
threads: 1
client_session_keep_alive: False
Code Build:
The build process will dynamically retrieve the confidential database connection information from Secret Manager or Parameter Store. It will then proceed to construct the source code and subsequently push it as an image to the private ECR repository.
Buildspec.yml
The yaml file defines a series of commands to be executed during different build phases. It sets up a Python environment, configures Snowflake credentials, builds and tags a Docker image, and pushes it to an Amazon ECR repository in the ap-southeast-2 region.
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
# SPDX-License-Identifier: MIT-0
version: 0.2
phases:
install:
runtime-versions:
python: 3.11
pre_build:
commands:
- aws --version
- echo 'region - ' - $AWS_DEFAULT_REGION
- echo 'repository - ' $REPOSITORY_URI
- cd src/dbt-project/
- sed -i -e "s/\(type:\).*/\1 $SNOWFLAKE_TYPE/" profiles.yml
- sed -i -e "s/\(account:\).*/\1 $SNOWFLAKE_ACCOUNT/" profiles.yml
- sed -i -e "s/\(user:\).*/\1 $SNOWFLAKE_USER/" profiles.yml
- sed -i -e "s/\(password:\).*/\1 $SNOWFLAKE_PASSWORD/" profiles.yml
- sed -i -e "s/\(role:\).*/\1 $SNOWFLAKE_ROLE/" profiles.yml
- sed -i -e "s/\(database:\).*/\1 $SNOWFLAKE_DATABASE/" profiles.yml
- sed -i -e "s/\(warehouse:\).*/\1 $SNOWFLAKE_WAREHOUSE/" profiles.yml
- sed -i -e "s/\(schema:\).*/\1 $SNOWFLAKE_SCHEMA/" profiles.yml
- sed -i -e "s/\(threads:\).*/\1 $SNOWFLAKE_THREADS/" profiles.yml
- cat profiles.yml
- cd ../
- echo Logging in to Amazon ECR
#- $(aws ecr get-login --region ap-southeast-2 --no-include-email)
- aws ecr get-login-password --region ap-southeast-2 | docker login --username AWS --password-stdin 590312749310.dkr.ecr.ap-southeast-2.amazonaws.com
build:
commands:
- echo Build started on `date`
- echo Building the Docker image...
- docker build -t ********.dkr.ecr.ap-southeast-2.amazonaws.com/jaydbt:latest .
- docker tag *******.dkr.ecr.ap-southeast-2.amazonaws.com/jaydbt:latest *******.dkr.ecr.ap-southeast-2.amazonaws.com/dbt:latest
post_build:
commands:
- echo Build completed on `date`
- echo Push the latest Docker Image...
- docker push 590312749310.dkr.ecr.ap-southeast-2.amazonaws.com/dbt:latestCode Build Environment Variable:
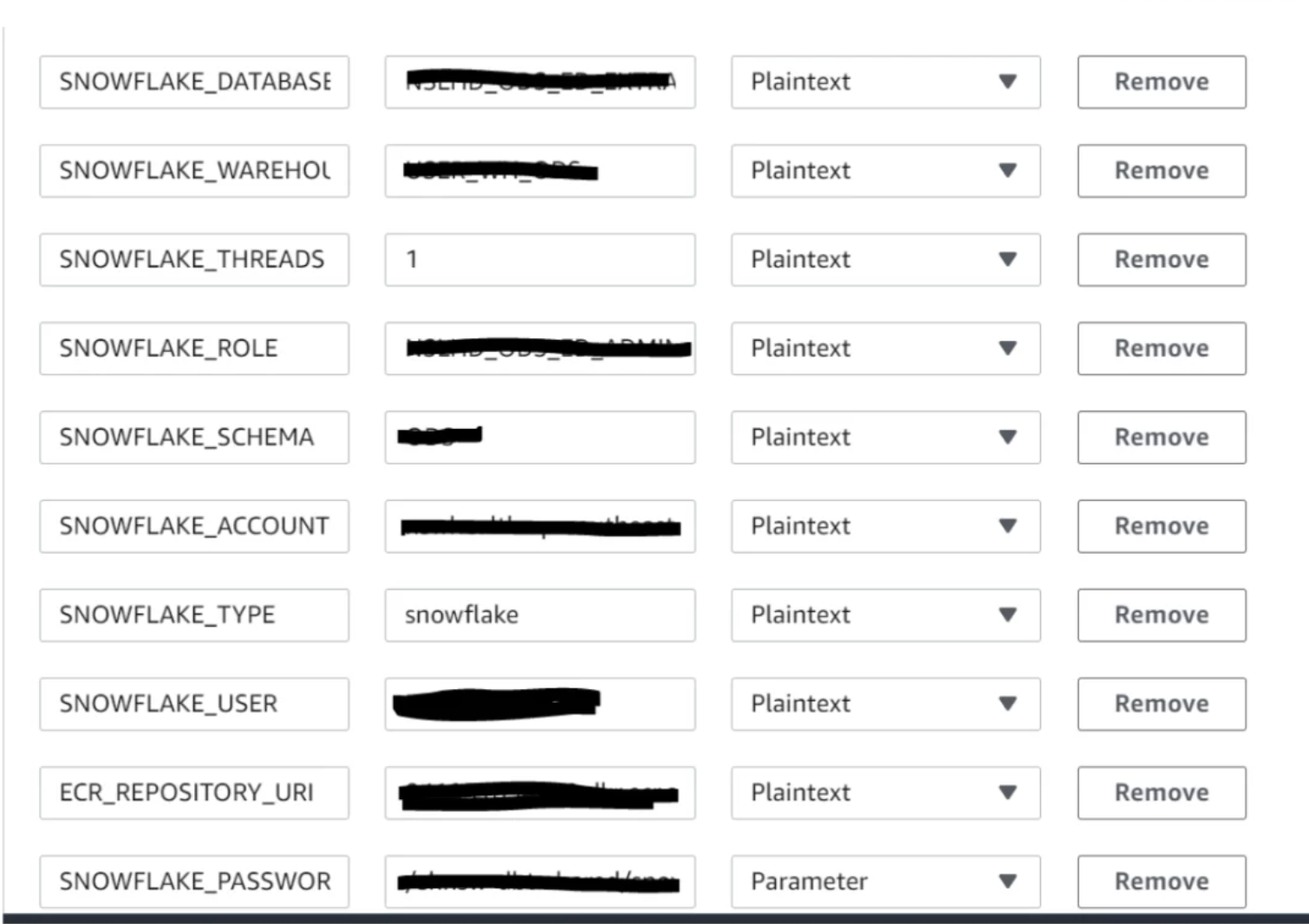 Code Build Param
Code Build Param
Up to this point, we’ve successfully compiled the code and uploaded our Docker image to the ECR Repository.
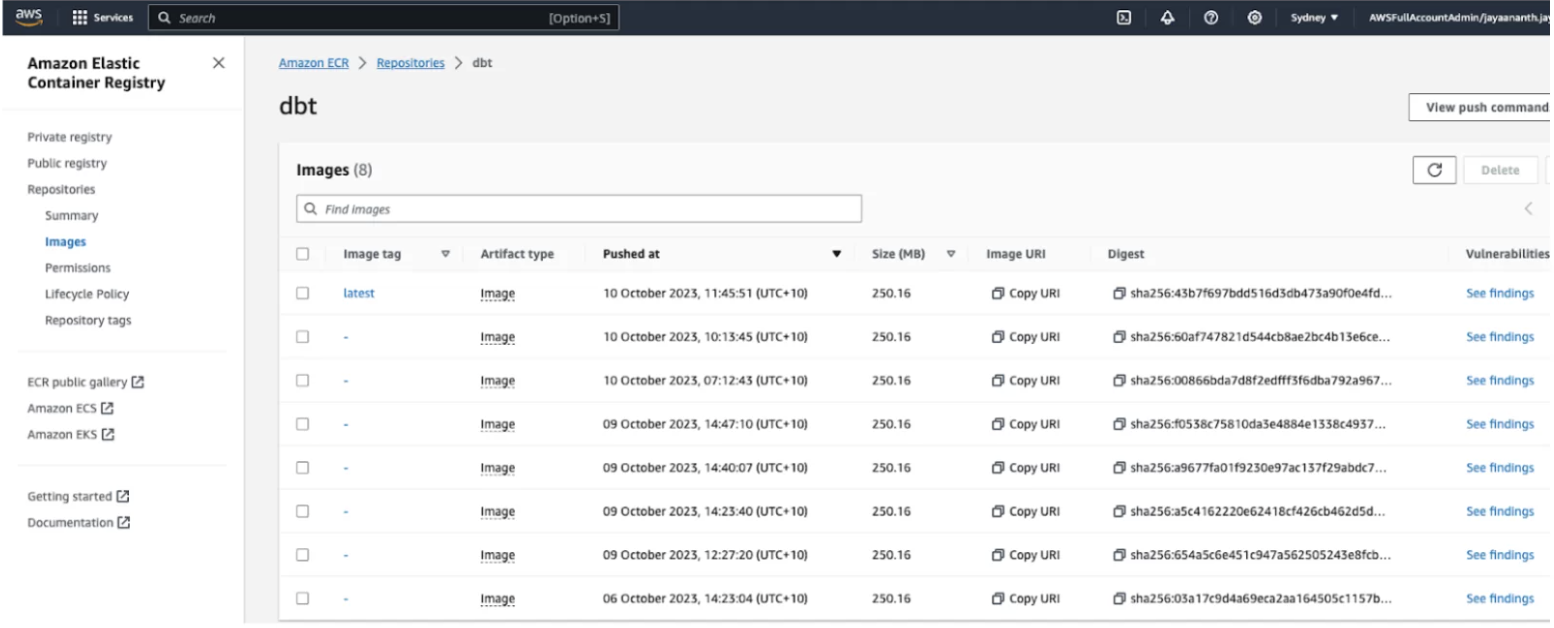 ECR
ECR
As an illustrative example, we will be writing a code in DBT to implement Slowly Changing Dimensions (SCD) type 2 using models and snapshots in the Snowflake environment.
DBT offers a feature called snapshots, which allows you to capture and track changes made to a table that can be updated over time. Snapshots are particularly useful for implementing type-2 SCDs on tables that can be modified.
source/sources.yml
1
2
3
4
5
6
7
8
9
10
version: 2
sources:
- name: customer
schema: dev
tables:
- name: emp_fact
identifier: emp_fact
- name: emp
identifier: employee
models/emp_fact.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
select employee.EMP_NO,
employee.FIRST_NAME,
employee.LAST_NAME,
employee.GENDER,
department.DEPT_NAME,
employee.UPDATED_AT
from employee join
dept_emp
on dept_emp.emp_no=employee.emp_no
join department
on department.dept_no=dept_emp.dept_no
snapshots/scd_emp.sql
{% snapshot scd_emp %}
{{
config(
target_schema='public',
unique_key='emp_no',
strategy='timestamp',
updated_at='updated_at',
invalidate_hard_deletes=True
)
}}
select * FROM {{ source('customer', 'emp') }}
{% endsnapshot %}Summary:
In this blog, we explored the process of configuring DBT on an ECR private repository via an AWS pipeline. In my next blog post, we will delve into the configuration of MWAA and demonstrate how to initiate the DBT job using Airflow.
Note: This article was originally published on Cevo Australia’s website
If you enjoy the article, Please Subscribe.